


Summary: A preview of 2026 separation science trends, from PFAS and SFC to metabolomics, next-generation HPLC columns, oligonucleotides, and ADC analysis.

Caroline West is a full professor in analytical chemistry at the University of Orleans, France. Her main scientific interests lie in the fundamentals of chromatographic selectivity, both in the achiral and chiral modes, mainly in SFC, but also in liquid chromatography (LC).
Summary: A preview of 2026 separation science trends, from PFAS and SFC to metabolomics, next-generation HPLC columns, oligonucleotides, and ADC analysis.

Caroline West highlights how advances in SFC instrumentation are driving greener, more versatile analytical workflows across diverse applications.
Caroline West highlights how advances in SFC instrumentation are driving greener, more versatile analytical workflows across diverse applications.
LCGC North America
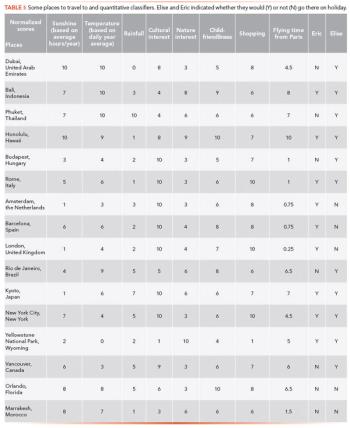
Decision trees offer great visuals to observe complex data sets and to classify data according to simple decision rules.
LCGC North America
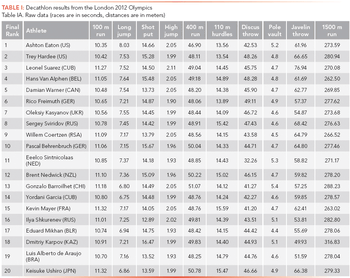
The sum of ranking differences (SRD) is a useful statistical tool for comparing methods, models, columns, or samples. It is also simple and straightforward.
Special Issues
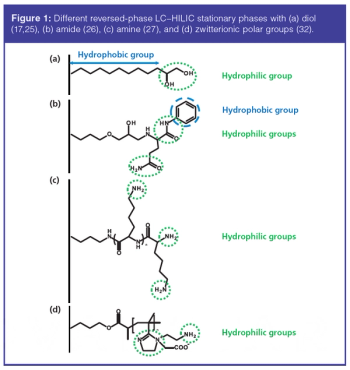
Mixed-mode high performance liquid chromatography (MM-HPLC) involves the combined use of two (or more) retention mechanisms in a single chromatographic system. Many original stationary phases have been proposed in recent years with promising possibilities, while applications have only started to appear in the literature. In this review, the authors discuss mixed-mode chromatography stationary phases. An overview of applications using mixed-mode chromatography is described, as well as the increased interest in mixed-mode systems for two-dimensional chromatography.

LCGC North America
Derringer desirability functions are a great favorite of mine because they are very simple and flexible. They may be applied to a variety of problems: whenever you need to select the “best” (sample, method, operating conditions etc.) from a set. It is also a convenient way to compare apples and oranges, whenever totally unrelated features must be ranked. They were first described by Derringer and Markham1 to select polymeric materials based on varied properties.
LCGC North America
Part V of this series takes a closer look at discriminant analysis (DA). Discriminant analysis is a supervised method, meaning that it involves some previous knowledge of your samples.

LCGC North America
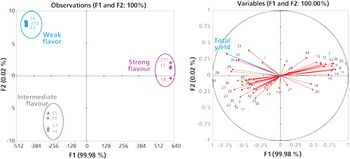
Part IV of this series takes a closer look at clustering. Clustering can be very useful at observing your data when the sample dimensionality is large. This is a barbarian term meaning that diversity among your samples may be wide. In that case, the space reduction provided by principal component analysis (PCA) is not always convincing, because the simplification provided by a single two-dimensional plot erases too much information. Clustering allows you to preserve more information.

LCGC North America
Keith Bartle talks about his proudest scientific achievements.

LCGC Europe
Keith Bartle, Emeritus Professor of Physical Chemistry and Visiting Professor in the Energy Centre of the University of Leeds, UK, has been a creative catalyst in a wide range of chromatographic collaborations stretching from the analysis of methane in air to printing inks. He spoke to Caroline West from the University of Orléans, in Orléans, France, about his career in chromatography and his proudest scientific achievements in separation science, including his research in supercritical fluid chromatography (SFC), gas chromatography (GC), and “the unified chromatograph”.

LCGC North America
Part III of this series takes a closer look at principal component analysis (PCA). PCA can be very useful for observing your data when the observations you wish to compare are described by many variables. It is a relatively easy way to obtain a simplified image of the data, while trying to maintain as much information as possible.

LCGC North America
This is part two of a series of tutorials that explain, in the simplest manner, how statistics can be useful, even to chromatographers who normally find statistics difficult, with a minimal understanding of its features. This part explains linear regressions.

LCGC North America
This is part one of a series of tutorials that explain, in the simplest manne, how statistics can be useful, even to chromatographers who normally find statistics difficult, with a minimal understanding of its features. Part I explains how to collect and examine your data.

LCGC North America
What exactly is SFC? Although you may have heard and read much about it recently, it is still rather vague to many a chromatographer.

LCGC Europe
The aim of this work was to find the optimal conditions to achieve sufficient limits of detection (LOD) that would permit the detection of neurotransmitters by LC–MS–MS in biological samples. An optimized HILIC–ESI–MS–MS system for the analysis of the 12 selected compounds was proposed.

LCGC Europe
The article investigates the ELSD response variation with supercritical carbon dioxide-based mobile phases and compares the response with HPLC.

LCGC North America
The mobile-phase flow rate and the amount of modifier mixed with carbon dioxide are the main parameters affecting peak area.

March 27th 2026
March 30th 2026

August 1st 2015


