

|Articles|August 1, 2017
- LCGC North America-08-01-2017
- Volume 35
- Issue 8
Celebrating 35 Years of LCGC
Author(s)The Editors of LCGC
Leading separation scientists share their perspectives on current challenges in separation science and where the field is heading.
Advertisement
In honor of LCGC’s 35th anniversary, we invited leading separation scientists to share their perspectives on current challenges in separation science that still need to be solved; their vision for what is to come-or should be coming-in separation science; or an important question or applications problem that can or should be solved by separation science.
Analytical Characterization of Biopharmaceuticals
Davy Guillarme
Protein biopharmaceuticals are emerging as an important class of drugs for the treatment of various diseases including cancer, inflammatory diseases, and autoimmune disorders. There is currently a wide variety of protein biopharmaceutical formats, but clearly the two most promising ones are monoclonal antibodies (mAbs) and antibody−drug conjugates (ADC). The success of these molecules is related to their obvious benefits in terms of safety and efficacy-more than 2000 biopharmaceuticals products are currently in clinical development, while 250 products have ever been approved for human use (1). So, the future of the biopharmaceutical market looks undoubtedly bright.
As illustrated in Figure 1, proteins, mAbs, and ADCs produced from living organisms have a complexity far exceeding that of small molecules and peptides produced from chemical synthesis. This additional complexity is related to some important sources of microheterogeneity observed in biopharmaceuticals that can occur during expression, purification, and long-term storage (that is, glycosylation, deamidation, oxidation, disulfide bridges scrambling, aggregation, and so on), as well as the fact that these small modifications must be characterized on a very large molecule. This inherent complexity can be well illustrated with mAbs, which possess a size of approximately 150 kDa, ± 1300 amino acids and several glycosylation sites. Despite the fact that only one single mAb is theoretically produced, there are always hundreds of possible variants that may exist, and all of them could contribute to the product efficacy and safety. Besides mAbs, ADCs further add to the complexity, since the heterogeneity of the original mAb is superimposed to the variability of the cytotoxic drug conjugation strategy. The ADC products are therefore often heterogeneous with respect to drug loading and its distribution on the mAb (2).
Today, there is a wide range of chromatographic approaches available for the successful characterization of mAbs and ADCs, as illustrated in Figure 2. Several nondenaturing approaches, including ion-exchange chromatography, size-exclusion chromatography (SEC), and hydrophobic-interaction chromatography (HIC), can be used for the separation of charge, size, and hydrophobic variants, respectively. However, these historical approaches, widely used by biochemists at the analytical and preparative scales, suffer from an inherent incompatibility with mass spectrometry (MS) because of the presence of a high salt concentration in the mobile phase. Therefore, some alternative MS-friendly strategies, such as reversed-phase liquid chromatography (LC) and hydrophilic-interaction chromatography (HILIC), have become more popular for the analytical characterization of proteins biopharmaceuticals.
In the last few years, all the approaches described above have been drastically improved to meet the analytical requirements of very complex biopharmaceutical products. Some progress was made in terms of chromatographic instrumentation and columns. Among the most important advances, we can cite the following development and commercial introductions:
- bio-inert LC systems, to limit protein adsorption onto the injector, tubing, and ultraviolet (UV) cell,
- highly inert stationary phases, which are particularly useful in SEC and reversed-phase LC modes to limit adsorption, secondary interactions, and peak distortion,
- wide-pore HILIC columns for directly characterizing the glycosylation profile at the intact protein level, even for large proteins of up to >100 kDa,
- wide-pore columns packed with sub-2-µm fully porous particles or sub-4-µm core-shell particles to drastically improve the kinetic performance in reversed-phase LC, SEC, and HILIC modes,
- stationary phases compatible with very high temperatures (up to 90−100 °C), which is mandatory to limit protein adsorption in reversed-phase LC and improve peak shape, and
- easy-to-use buffers for pH gradients from 5.6 to 10.2, in replacement of the salt gradients commonly used in ion-exchange chromatography (3).
All these new features explain why the achievable performance of chromatographic approaches are better today than the electrophoretic approaches (in gel or capillary formats), which were the reference techniques for proteins analysis for a long time.
However, taking into account the inherent complexity of biopharmaceutical samples, all these efforts in terms of chromatographic improvements are still often insufficient to deal with such complex samples containing numerous closely related variants. This complexity is why there are still a lot of attempts to combine chromatographic strategies in a two-dimensional (2D) setup (comprehensive, selective 2D, or heart-cutting) both in academic laboratories and the biopharmaceutical industry. There are primarily two main reasons for using 2D-LC: First, complementary information on protein variants can be gained from the two dimensions of separation in a single analysis and high resolving power is expected; and second, enabling the hyphenation of nondenaturing approaches (ion-exchange chromatography, SEC, and HIC) to an MS detector to see the identity of the observed chromatographic peaks (4). Virtually, all of the above mentioned chromatographic techniques (that is, ion-exchange chromatography, SEC, HIC, reversed-phase LC, and HILIC) can be combined together. In practice, the second dimension of the 2D setup often includes reversed-phase LC (directly MS-compatible, thanks to the use of a volatile mobile phase) and sometimes SEC (possible separation of salts and proteins from the first dimension under nondenaturing conditions). Numerous 2D combinations have been tested for the characterization of mAbs and ADCs, in combination with MS detection:
- SEC × reversed-phase LC was used to characterize free drug species in ADC samples (5)
- ion exchange × reversed-phase LC was used to compare originator and biosimilar mAbs at the protein level (6), but also for characterizing ADC samples (7)
- HIC × reversed-phase LC was used to assess the drug loading, distribution, and conjugation sites of an ADC sample, as shown in Figure 3 (8)
- HILIC × reversed-phase LC, reversed-phase LC × reversed-phase LC, and ion exchange × reversed-phase LC modes were used to characterize mAbs at the peptide mapping level (9)
Besides these examples, there are many other ways to combine chromatographic dimensions in a 2D-LC setup for characterizing mAb and ADC samples. With the increasing complexity of some new mAb formats (that is, bispecific mAbs [bsAbs], antibody-dual-drug conjugates [ADDCs], and so on), and the need to perform comparability studies between originator and biosimilar products, the future of 2D-LC looks brilliant.
Acknowledgments
The author wishes to thank the Swiss National Science Foundation for support (Grant 31003A_159494).
References
- G. Walsh, Nat. Biotechnol. 32(10), 992–1000 (2014).
- A. Beck, L. Goetsch, C. Dumontet, and N. Corvaïa, Nat. Rev. Drug Discov. 16(5), 315–337 (2017).
- S. Fekete, D. Guillarme, P. Sandra, and K. Sandra, Anal. Chem. 88, 480–507 (2016).
- D.R. Stoll, J. Danforth, K. Zhang, and A. Beck, J. Chromatogr. B 1032, 51–60 (2016).
- R.E. Bisdall, S.M. McCarthy, M.C. Janin-Bussat, M. Perez, J.F. Heuw, W. Chen, and A. Beck, mAbs 8(2), 306–317 (2016).
- M. Sorensen, D.C. Harmes, D.R. Stoll, G.O. Staples, S. Fekete, D. Guillarme, and A. Beck, mAbs 8(7), 1224–1234 (2016).
- K. Sandra, G. Vanhoenacker, I. Vandenheede, M. Steenbeke, M. Joseph, and P. Sandra, J. Chromatogr. B 1032, 119–130 (2016).
- M. Sarrut, A. Corgier, S. Fekete, D. Guillarme, D. Lascoux, M.C. Janin-Bussat, A. Beck, and S. Heinisch, J. Chromatogr. B 1032, 103–111 (2016).
- G. Vanhoenacker, I. Vandenheede, F. David, P. Sandra, and K. Sandra, Anal. Bioanal. Chem. 407, 355–366 (2015).
- M. Sarrut, S. Fekete, M.C. Janin-Bussat, O. Colas, D. Guillarme, A. Beck, and S. Heinisch, J. Chromatogr. B 1032, 91–102 (2016).
Davy Guillarme is with the School of Pharmaceutical Sciences at the University of Geneva, University of Lausanne in Geneva, Switzerland.
Seeking the Holy Grail-Prediction of Chromatographic Retention Based Only on Chemical Structures
Paul R. Haddad
Over the last decade method development in liquid chromatography (LC) has become an increasingly difficult challenge. Apart from the wide range of chromatographic techniques available, the number of stationary phases that can be used for each technique has increased enormously. Taking reversed-phase LC as an example, there are more than 600 stationary phases from which to choose.
It is convenient to divide method development into two distinct steps. The first is the “scoping” phase, which involves selecting the most appropriate chromatographic technique (reversed-phase LC, hydrophilic-interaction chromatography [HILIC], ion-exchange chromatography, and so on), the stationary phase most likely to yield the desired separation, and the broad mobile-phase composition. The second is the “optimization” phase, wherein the precise mobile-phase composition, flow rate, column temperature, and so forth, are determined. The scoping phase of method development, especially in large industries, has traditionally followed a path whereby a mainstream chromatographic technique is chosen (usually reversed-phase LC), a limited number of stationary phases are then considered (often defined by the range of stationary phases available in the laboratory at the time), and preliminary scouting experiments are performed experimentally on these phases. This approach can prove to be a very costly exercise and often needs to be repeated if, for example, the initial choice of the chromatographic technique was incorrect.
A very attractive alternative would be to conduct the scoping phase of method development by predicting the retention times of the analytes of interest on a range of chromatographic techniques and for a wide range of stationary phases. If this approach were possible, then the selection of chromatographic technique and stationary phase could be made with confidence and all the experimental aspects of method development could be confined to the optimization phase. Note that the accuracy of retention time prediction required for successful scoping need not be excessive, and predictions with errors of about 5% or less could be used for this purpose. In recent years, there has been strong interest in predicting retention of analytes based only on their chemical structures. These studies use quantitative structure-retention relationships (QSRRs), which provide a mathematical relationship between the retention time of an analyte and some properties of that analyte that can be predicted from its structure. These properties may be conventional physicochemical properties, such as molecular weight, molecular volume, polar surface area, logP, logD, and so forth. However, such physicochemical properties are often too limited in number to give accurate prediction models, so researchers frequently use molecular descriptors derived from molecular modeling based on the analyte’s structure. These molecular descriptors may number in the thousands and are derived from one-, two- and three-dimensional (1D, 2D, and 3D) calculations from the chemical structure.
A typical QSRR procedure follows the scheme in Figure 1. First, one needs a database (as large as possible) of known analytes with known structures and retention times for a specified chromatographic condition. As shown in Figure 1, a subset (the training set) consisting of the most relevant analytes in the database is selected and is used to build the desired QSRR mathematical model. One means to select the training set of analytes is to use only those analytes that are chemically similar (as determined by some mathematical similarity index) to the target compound for which retention is to be calculated. Because the number of available molecular descriptors can be very high, it is usually necessary to find those descriptors that are most significant in determining retention. This is called the feature selection step. Finally, the developed model needs to be validated to determine its accuracy of prediction. After the QSRR model has been validated it can then be used to calculate retention time of a new compound simply by calculating the relevant molecular descriptors for that compound (using only its chemical structure) and inserting those descriptors into the model. It should be noted that there is no attempt to derive a “universal” QSRR model applicable to all analytes. Rather, a new “local” model is calculated for each new analyte by identifying the best training set for that specific analyte.
The above process works well, and Figure 2 shows an example wherein the prediction of retention for three groups of four analytes on a HILIC amide stationary phase was performed with excellent accuracy. Retention times for 13 benzoic acids were measured at each experimental point in the experimental design shown on the left. Retention data were predicted for four new benzoic acid analytes at each of the mobile-phase compositions in the experimental design. These predicted retention times were used to construct a color-coded risk of failure map (using a failure criterion of α < 1.15) with the optimal combination of pH and % acetonitrile shown (center), while on the right is the actual chromatogram obtained at the predicted optimal mobile phase, together with the predicted retention times shown as red lines (1). The average error of prediction was 3.8 s, and this level of accuracy was obtained for analytes never seen in the modeling step and at a mobile-phase composition that had not been used in the experimental design.
It is clear that QSRR modeling can achieve the level of accuracy desired for the scoping phase of method development. However, there are some important limitations. The first of these is the need for extensive retention data. To be successful, the QSRR modeling requires that the database contains sufficient chemically similar compounds to enable identification of a training set of at least 7−10 compounds. Second, if the database contains retention data measures for one stationary phase at one mobile-phase composition then all predictions of retention can be made only under those conditions. The second limitation can be overcome by changing the target of the model from retention time to some fundamental parameters that allow calculation of retention time. One example of this approach is in ion-exchange chromatography, where retention is governed by the linear solvent strength model (2):
log k = a - b log [Ey-] [1]
where k is the retention factor, [Ey-] is the molar concentration of the eluent competing ion (mol/L), and a and b values are the intercept and the slope, respectively. If QSRR models are built for the a- and b-values in equation 1, then retention factor (and retention time) can be calculated for any mobile-phase composition. The same approach can be used for other chromatographic techniques, such as by modeling the analyte coefficients for the hydrophobic subtraction model in reversed-phase LC (3).
The first limitation discussed above remains the biggest obstacle to successful implementation of QSRR modeling, especially in reversed-phase LC because of the huge diversity of analytes and stationary phases involved. The creation of sufficiently diverse and reliable databases will be beyond the reach of any individual organization and will be possible only through extensive networking and collaborations. Crowd sourcing data might be one way to acquire the data, but the requirements for structured procedures and validated results will probably render this approach impractical. On the other hand, consortium arrangements between large industrial organizations, such as pharmaceutical companies, could be the solution since these organizations share the same general method development problems and they are accustomed to the stringent requirements for the accuracy of chromatographic data.
Until sufficient databases are generated, the full potential of QSRR modeling will not be realized and the “Holy Grail” will remain elusive. However, the opportunity to predict retention solely from chemical structure remains a highly desirable outcome.
Acknowledgment
The author acknowledges the contributions to this project from the following collaborators: Maryam Taraji (UTAS), Soo Park (UTAS), Yabin Wen (UTAS), Mohammad Talebi (UTAS), Ruth Amos (UTAS), Eva Tyteca (UTAS), Roman Szucs (Pfizer), John Dolan (LC Resources), and Chris Pohl (Thermo Fisher Scientific).
References
- M. Taraji, P.R. Haddad, R.I.J. Amos, M. Talebi, R. Szucs, J.W. Dolan, and C.A. Pohl, Anal. Chem. 89, 1870–1878 (2017).
- S. Park, P.R. Haddad, M. Talebi, E. Tyteca, R.I.J. Amos, R. Szucs, J.W. Dolan, and C.A. Pohl, J. Chromatogr. A 1486, 68–75 (2017).
- L.R. Snyder, J.W. Dolan, and P.W. Carr, J. Chromatogr. A 1060, 77 (2004).
Paul R. Haddad is an emeritus distinguished professor with the Australian Centre for Research on Separation Science (ACROSS) at the University of Tasmania in Tasmania, Australia.
The Need for Improvements in Ultratrace Analysis for Biological and Environmental Analysis
Susan Olesik
Analytical chemists continue to develop methods for ultratrace-level analyses that are used by practitioners in areas such as environmental, human health studies, and process technology. However, questions continue to arise about whether the current methods are adequate. This article describes global challenges that point to the need for significant disruptive technology in analytical chemistry.
Endocrine disruptors either mimic or block the production of naturally occurring hormones. Compounds known to be endocrine disruptors include parabens, triclosan, polychlorinated biphenyls, bisphenol A, dioxin, flame retardants, plasticizers, and some pharmaceuticals. Adverse neurological, developmental, and reproductive defects occur in both humans and wildlife as a result of endocrine disruptors. For many of these compounds, the minimum concentration level that will not affect the endocrine systems is not yet known. Mixtures of endocrine disruptors or mixtures with other compounds at ultratrace levels may be implicated in the actual endocrine disruption (1).
Similarly, oxidative stress on humans and wildlife because of exposure to ultratrace levels of pollutants is also of significant concern. Oxidative stress is suspected in neurodegenerative diseases such as Alzheimer’s disease, Parkinson’s disease, and multiple sclerosis. Ecotoxicity in the form of oxidative stress is also a rising concern. Increasing evidence shows that very low levels of compounds, or perhaps mixtures of low levels of different compounds, may be causing oxidative stress conditions in biota. Escher and colleagues showed that 99.9% of the observed chemically induced oxidative stress was because of unknown compounds or combinations of these compounds (2). In other words, less than 0.1% of the measured oxidative stress was because of known measured compounds when more than 269 compounds were studied. Solid-phase microextraction (SPME)−ultrahigh-pressure liquid chromatography−tandem mass spectrometry (UHPLC−MS/MS) analyses are typical for these studies, but clearly the detection limits are not low enough.
Similarly, in human health studies and analyses of molecules involved in human biology, scientists are moving away from monitoring single biomarkers to multiplex biomarkers or comprehensive molecular profiling (3). Increasingly, ultratrace levels of compounds in mixtures of biologically relevant analytes with large ranges of concentration seem important in controlling significant biological processes (4).
Current analytical devices are not meeting all of the needs for ultratrace-level detection as described above. We must develop new means to lower the detection limits of organic and biological compounds. The extent of the enhancement needed is unknown at this point. Methods with increased selectivity are also required for many of these complex analyses. Clearly, further improvements in preconcentration capabilities with solid-phase extraction (SPE) and in chromatographic efficiency must occur. These improvements will facilitate improved detection limits for the analysis of small to medium organic compounds. In addition, MS detection limit improvements are needed.
Several research groups are developing new materials to begin to meet these substantial challenges. My group is developing new nanobased technology that is improving SPME (5), chromatography (6,7), and MS (8,9). The nanofibrous extraction devices improve the extraction efficiencies to as much as 30 times compared to commercial devices (5). The nanofiber-based planar chromatography provides efficiencies that are comparable to (7) or much larger (6) than high performance liquid chromatography (HPLC), and the nanofibrous surfaces when used for surface-assisted laser desorption ionization (SALDI) MS provide detection limits down to attomolar quantities (8,9).
To summarize, analytical chemists must push forward to move detection limits lower and continue to improve the selectivity of our analyses. When these goals are met, the analytical community will contribute strongly to the health and environmental benefits of society. To my fellow scientists: Please accept this challenge!
References
- L.B. Barber, J.E. Loyo-Rosales, C.P. Rice, T.A, Minarik, and A.K. Oskouie, Sci. Total Environ. 517, 195–206 (2015).
- B.I. Escher, C. van Daele, M. Dutt, J.Y.M. Tang, and R. Altenburger, Environ. Sci. Technol. 47, 7002–7011 (2013).
- M. Kaufmann, M. Keppens, and E.D. Blair, Per. Med. 12, 389–403 (2015).
- J.M. Leung, V. Chen, Hollander, D. Dai, S.J. Tebbutt, S.D. Aaron, K.L. Vandemheen, S.I. Rennard, J. M. FitzGerald, P.G. Woodruff, S.C. Lazarus, J.E. Connett, H.O. Coxson, B. Miller, C. Borchers, B.M. McManus, R.T. Ng, and D.D. Sin, PLOS One 11, 1–12 (2016).
- T. Newsome, J. Zewe, and S.V. Olesik, J. Chromatogr. A 1262, 1–7 (2012).
- J.E. Clark and S.V. Olesik, J. Chromatogr. A 1217, 4655–4662 (2010).
- Y. Wang and S.V. Olesik, Anal. Chim. Acta 970, 82–90 (2017).
- J. Bian and S.V. Olesik, Analyst 142, 1125–1132 (2017).
- T. Lu and S.V. Olesik, Anal. Chem. 85, 4384–4391 (2013).
Susan Olesik is a professor and chair in the Department of Chemistry and Biochemistry at The Ohio State University in Columbus, Ohio.
Measuring Water: The Expanding Role of Gas Chromatography
Daniel W. Armstrong
The accurate measurement of water content is an importunate and ubiquitous task in industrial and scientific laboratories worldwide. Water content is probably measured in a wider variety of matrices and at a greater range of concentrations (that is, less than parts per million to 99% +) than any other analyte. It must be measured in raw materials, final products, and a variety of natural systems. Often, there is a regulatory mandate to measure water in certain products including pharmaceuticals, foods, and other consumer products. Further complicating these measurements is the fact that water is an omnipresent impurity, which particularly complicates the accuracy and precision of any technique used to analyze samples for low levels of moisture.
Various analytical methods have been developed for the determination of water content. However, selection of the best method depends on the nature of the sample to be analyzed, the amount of water present, and the ultimate purpose of the information. Analytical approaches can differ completely for solid versus liquid versus gaseous samples or for trace versus moderate to high levels of water. A broadly useful technique that can be used for most sample types is highly desirable. Traditionally, the dominant approach for quantitating water has been Karl Fischer titration (KFT) despite its well-known limitations and inaccuracies (1). Recent developments in gas chromatography (GC) have elevated it to a position to challenge KFT. This change is largely the result of the development of new columns (based on ionic liquids) and detectors that are sensitive to water (1−5). Additionally, the ease of using capillary GC by either direct injection or in headspace formats greatly expands the types of samples that can be analyzed.
Ionic liquid stationary phases are known to have good thermal stability, but they are also completely stable in the presence of water and oxygen at high temperatures, so much so that humid air can be used as a carrier gas (see Figure 1). Obviously, a GC stationary phase that is used to separate water from other substances cannot be altered or degraded by water. Furthermore, the column must produce water peaks of good efficiency and symmetry so that area integration is accurate and reproducible. Finally, ionic liquid-based columns have optimal selectivity for separating water from a wide variety of polar and nonpolar substances (see Figure 2).
Three ionic liquid stationary phases were specifically developed for the separation and quantitation of water. Their structures are shown in Figure 3. These stationary phases have somewhat varied polarities and selectivities that provide optimal separations for different types of samples and matrices (vide infra). Equally important is the advent of new highly sensitive and “universal” GC detectors such as the barrier ionization discharge and vacuum ultraviolet detectors as well as advanced “ultradry” headspace devices (1−5). The determination of trace levels of water in any sample is dependent on the degree to which carrier and purge gases can be dried as well as the extent to which one can exclude atmospheric moisture from the entire analysis process. In fact, commercial gases (He, N2, He, Ar, and more) labeled as dry or anhydrous should not be used for ultratrace-level water determinations without further extensive purification (1). For example, the analysis of trace-level water in petroleum products (see Figures 4 and 5) require exceedingly dry conditions (1). Both the chromatographic quality and limit of detection (LOD) of the separation represented in Figure 4 could not be duplicated with a less sensitive detector (for water) or with moisture contamination of the flow gas or the rest of the system.
6).
150 °C at 5 °C/min (hold at150 °C for 15 min), total = 40 min; carrier gas: helium; linear velocity: 45 cm/s. Note that the limit of detection (LOD) and limit of quantitation (LOQ) for water were determined to be 0.22 and 0.66 ppm, respectively. Adapted with permission from the Shimadzu App. Data Sheet No. 18, 2017.
The preferred approach for solid samples is headspace GC. The solid samples are dissolved in a headspace solvent in a purged-sealed vial. The vial and sample are heated to enhance the moisture content in the headspace, which is sampled and injected into the GC. For such analyses, it has been found that dry ionic liquids make the best headspace solvents since they are nonvolatile and do not show up in the chromatogram as do all other headspace solvents (1,2,5). This approach has been shown to be effective for pharmaceutical products and their active pharmaceutical ingredients (APIs) (2,5). Headspace GC also is an effective approach for quantitating water in many types of food products (4,6). Also, both water and ethanol are easily measured in most alcoholic beverages and all other solvents using either direct injection or headspace GC (3,7).
The new instrumentation specifically designed for GC water analysis (for example, columns, detectors, headspace samplers, and flow gas purifiers) make GC the first truly competitive and often superior approach to KFT. Its speed, accuracy, and ease of automation offer advantages that are difficult to match with KFT or other techniques. Finally, very little sample is needed for direct GC or headspace GC (from about 0.50 to 500 µL, respectively). It appears that with the recent developments in GC and headspace GC, they are well positioned to make a significant impact in the way in which water is measured.
Acknowledgment
Structures and some material for figures were supplied by Leonard M. Sidisky, Millipore Sigma.
References
- L.A. Frink and D.W. Armstrong, Anal. Chem.88, 8194–8201 (2016).
- L.A. Frink, C.A. Weatherly, and D.W. Armstrong, J. Pharma. Biomed. Anal.94, 111–117 (2014).
- C.A. Weatherly, R.M. Woods, and D.W. Armstrong, J. Agricultural and Food Chem.62, 1832–1838 (2014).
- L.A. Frink and D.W. Armstrong, Food Chem.205, 23–27 (2016).
- L.A. Frink and D.W. Armstrong, J. Pharm. Sci.105, 2288–2292 (2016).
- L.A. Frink and D.W. Armstrong, LCGC North Am., “Advances in Food and Beverage Analysis” supplement 34(s10), 6–13 (2016).
- D.A. Jayawardhana, R.M. Woods, Y. Zhang, C. Wang, and D.W. Armstrong, LCGC Europe24, 516–529 (2011).
Daniel W. Armstrong is the Robert A. Welch Distinguished Professor in the Department of Chemistry and Biochemistry at The University of Texas at Arlington in Arlington, Texas.
Multidimensional Liquid Chromatography Is Breaking Through
Dwight R. Stoll
I recently attended the 45th International Symposium on High Performance Liquid Phase Separations and Related Techniques (HPLC 2017) conference in Prague, Czech Republic, in June. As usual it was a great meeting with excellent talks and poster presentations describing recent research in the field of liquid-phase separations. I was struck, though, by the level of attention paid to multidimensional separations that simply was not as evident in past meetings. Indeed, in the plenary talks by Professors Gert Desmet and Pat Sandra, they both discussed the point that to significantly improve the performance of liquid chromatography (LC) from where we are now, we need to move from one-dimensional (1D) to two-dimensional (2D) separations. This concept is not new of course (1), but advances in theory and instrumentation have put nonexperts in a position to use 2D-LC, in particular, more routinely and to solve a wide variety of analytical challenges (2).
So then, where do we go from here? Although some experienced scientists using 2D-LC in industry are convinced that it is “here to stay” and will have a role larger than that of a niche technique (3), it is not yet clear what share of all LC separations will be 2D separations in say, five years from now. Questions about cost, ease of use, robustness, and so on are important to many potential users who are considering 2D-LC, but have not committed yet. A few years ago one of the most important questions we talked about as affecting the scope of application of 2D-LC had to do with whether or not 2D-LC methods would find their way into use in regulated environments (that is, in quality control [QC] labs). Now, it seems we have at least a tentative answer to that question. In just the past year, two publications have described the development of 2D-LC methods intended for use in QC environments. The first, described by Largy, Delobel, and coworkers describes a heartcutting 2D-LC–mass spectrometry (MS) method for analysis of a protein therapeutic drug (4). The second, described by Yang, Zhang, and colleagues involves a heartcutting 2D-LC method for analysis of a small-molecule drug. Very importantly, this group demonstrated that their 2D method could be validated by adapting the existing validation framework normally used for 1D methods (5).
In my view, the most important questions that will affect further development and adoption of 2D-LC in the next few years have to do with method development. At this point I think it is fair to say that users new to 2D-LC find the number of method development variables a bit overwhelming. The question is, how can we develop concepts, strategies, and perhaps instrument components that help to simplify and streamline method development without sacrificing the performance potential of the technique? We are starting to see the building blocks of such strategies develop. For example, a number of groups have picked up on the idea of Pareto optimality to maximize peak capacity of 2D separations as a function of analysis time (6,7). Peter Schoenmakers’s group has also demonstrated the application of software developed for the purpose of maximizing the resolution of a particular sample by 2D-LC (8). At the HPLC 2017 meeting, Dr. Kelly Zhang described efforts by her group at Genentech to simplify column selection in 2D-LC method development (9). This is a very important and exciting development, which will undoubtedly have a big impact on the field.
While I agree with Dr. Venkatramani that 2D-LC is “here to stay” (3), it is of course difficult to predict just how much growth we will see in the next few years. I believe a compelling case can be made from recently published literature that 2D-LC can be used to both provide significantly more resolving power than 1D-LC, but in the same analysis time, and to significantly improve the speed of separation relative to 1D-LC, but without sacrificing resolution (for example, see references 10 and 11). Now, it is up to users to realize this performance potential, and the extent to which they do so will depend on how easily it can be done. At the moment there is tremendous growth in the use of 2D-LC for characterization of biopharmaceutical materials (12), which are becoming more complex by the day. I believe scientists working in this space and others will increasingly find “two-for-one” analyses like that described recently by a group from the U.S. Food and Drug Administration for the characterization of therapeutic antibodies in crude bioreactor supernatant (13) too good to refuse. Stay tuned!
References
- J.C. Giddings, Anal. Chem.56, 1258A–1270A, doi:10.1021/ac00276a003 (1984).
- D.R. Stoll and P.W. Carr, Anal. Chem.89, 519–531, doi:10.1021/acs.analchem.6b03506 (2017).
- C.J. Venkatramani, “High Resolution Analysis of Linker Drugs Used in Antibody Drug Conjugates (ADCs) by 2D-LC-MS: Transition of 2D-LC-MS from Research to Main Stream Pharmaceutical Analysis,” presented at the 45th International Symposium on High Performance Liquid Phase Separations and Related Techniques (HPLC 2017), Prague, Czech Republic, 2017.
- E. Largy, A. Catrain, G. Van Vyncht, and A. Delobel, Current Trends in Mass Spectrometry14(2), 29–35 (2016).
- S.H. Yang, J. Wang, and K. Zhang, J. Chrom. A 1492, 89–97, doi:10.1016/j.chroma.2017.02.074 (2017).
- M. Sarrut, A. D’Attoma, and S. Heinisch, J. Chrom. A1421, 48–59, doi:10.1016/j.chroma.2015.08.052 (2015).
- G. Vivó-Truyols, S. van der Wal, and P.J. Schoenmakers, Anal. Chem.82, 8525–8536, doi:10.1021/ac101420f (2010).
- B.W.J. Pirok, S. Pous-Torres, C. Ortiz-Bolsico, G. Vivó-Truyols, and P.J. Schoenmakers, J. Chrom. A1450, 29–37, doi:10.1016/j.chroma.2016.04.061 (2016).
- K. Zhang, “Multiplexed mLC-nLC for Comprehensive Impurity Profiling: A Method Development ‘Free’ Platform,” presented at the 45th International Symposium on High Performance Liquid Phase Separations and Related Techniques (HPLC 2017), Prague, Czech Republic, 2017.
- M. Sarrut, F. Rouvière, and S. Heinisch, J. Chrom. A1498, 183–195, doi:10.1016/j.chroma.2017.01.054 (2017).
- L.W. Potts and P.W. Carr, J. Chromatogr. A1310, 37–44, doi:10.1016/j.chroma.2013.07.102 (2013).
- D. Stoll, J. Danforth, K. Zhang, and A. Beck, J. Chrom. B1032, 51-60, doi:10.1016/j.jchromb.2016.05.029 (2016).
- A. Williams, E.K. Read, C.D. Agarabi, S. Lute, and K.A. Brorson, J. Chrom. B 1046, 122–130, doi:10.1016/j.jchromb.2017.01.021 (2017).
Dwight Stoll is an associate professor and co-chair of chemistry at Gustavus Adolphus College in St. Peter, Minnesota.
Redefining Simplicity in Ionization: Discovery and Implementation of Novel Ionization Processes in Mass Spectrometry
Sarah Trimpin
Mass spectrometry (MS) is a powerful tool for characterizing exceedingly low amounts of compounds in complex materials by separating gaseous ions according to their mass-to-charge ratio (m/z) with exceedingly high mass resolving power (>106 m/Δm, 50% peak overlap at low m/z) for some instruments. A severe MS limitation, for a number of years, was the inability to convert nonvolatile compounds to the gas-phase ions. Electrospray ionization (ESI) and matrix-assisted laser desorption-ionization (MALDI) are the most prominent ionization methods to open MS to the analysis of nonvolatile and high-mass compounds, including proteins. Specialized mass spectrometers and ion sources were built, beginning in the late 1980s, to accommodate these powerful ionization methods despite disagreements over ionization mechanisms and the knowledge needed to enhance them. For almost 30 years, considerable effort has gone into improving instrumentation relative to these ionization methods.
More recently, ionization processes were discovered and developed into analytical ionization methods that produce ions from various materials by solely having either a small-molecule solid or solvent matrix present when exposed to the subatmospheric pressure at the mass spectrometer inlet (1). The simplest of these methods, matrix-assisted ionization (MAI), spontaneously transfers compounds into gas-phase ions without the need for voltage, photons, or even added heat (2). While the fundamentals are not yet well understood, these simple processes have excellent sensitivity with low attomole limits of detection (3) and produce clean full-scan mass spectra requiring only a few femtomoles of samples such as drugs and peptides. In spontaneous ionization any means of introducing the matrix-analyte sample into the sub-atmospheric pressure of the mass spectrometer produces analyte ions.
MAI is part of a family of inlet and vacuum ionization technologies that achieve charge separation primarily through temperature and pressure differential with or without the aid of collisions. In these ionization processes, the matrix is key, and it can be a solid or a solvent that is introduced to the subatmospheric pressure with (for example, tapping) or without (that is, by direct insertion) the use of a force. In any case, the use of a laser, high voltage, and nebulizing gas is not necessary and clogged capillaries are eliminated--all items that increase cost of analysis and subject the analysis to failure. Gas-phase ions are observed multiply-protonated or deprotonated, depending on the polarity selected by the mass spectrometer, just like in ESI, even using aprotic matrices such as 3-nitrobenzonitrile (3-NBN) (4,5). MAI matrices that require no heat sublime in vacuum, and thus are pumped from the mass spectrometer ion optics, similar to solvents used with ESI. Heating the ion transfer tube of the mass spectrometer increases the number of matrices capable of producing high sensitivity even from solutions; this technique is called solvent-assisted ionization (SAI) (6). SAI and a related technique, voltage-SAI, were used with liquid chromatography (LC) to achieve higher sensitivity than LC–ESI-MS without the need for nebulizing gases or special emitters (7,8).
The initial developments of these technologies were accomplished using commercial ion sources of different vendors’ mass spectrometers. However, most commercial sources are not equipped for optimum MAI. Efforts designing and building dedicated inlets promise a better understanding, performance, and universal vendor applicability of the new ionization processes (9). Consequently, in collaborative efforts, dedicated sources are being developed that allow complex samples to be directly analyzed using a probe-type vacuum introduction to any mass spectrometer (10), and tube inlets for sample introduction directly from atmospheric pressure with and without LC (11), manually and automated. For example, complex mixtures can now be acquired in seconds directly from biological fluids, tissue, or buffered solution without any potential cross-contamination (Figure 1), or from surfaces such as dollar bills using a vacuum cleaner approach in a contactless fashion. By placing matrix only on the feature of interest on a surface (Figure 1b) and exposing the surface to the vacuum of the mass spectrometer, ions are observed from compounds exposed to the matrix solution allowing direct, rapid interrogation of “features of interest.” With direct analysis of biological materials, the extreme complexity can be overwhelming (Figure 1c), and additional separation, other than m/z, is desirable. Ion mobility spectrometry (IMS) interfaced to MS adds another nearly instantaneous gas-phase separation (Figure 1d) cleanly separating proteins from the lipid ions contained in the tissue and providing distinctive drift-time distributions for each ion, similar to the retention time in LC–ESI-MS. IMS also increases the dynamic range of an experiment; however, it does not address the issue of ion suppression in mixtures. Ion suppression is best reduced by a separation process before ionization, but solvents used in LC also contribute to ion suppression effects in ESI. Other reasons for using LC before MS include improved quantitation, especially when isotopic internal standards are not available. Combining LC or IMS with high-resolution MS and MS/MS provides exceptionally powerful approaches for analysis of complex mixtures (12). However, there are numerous instances where the added difficulty, time, and cost can be eliminated by using direct ionization methods as witnessed by the growth in so-called ambient ionization (13).
Inlet ionization methods are well suited either for single- or multiple-sample analyses. One of the first such demonstrations was a multiplexed, contactless SAI method rapidly characterizing sample composition from well-plates using imaging software (14). Taking full advantage of simple, flexible, rapid, and robust ionization technology, an automated prototype platform was developed capable of MAI, SAI, vSAI, and ESI from 384-well plates. For example, automated MAI-MS within approximately 6 s analyzed lysozyme, 14.3 kDa, from a single well at 140,000 mass resolution (Figure 2).
As with any unique new ionization process, the range of applicability will expand--as has already been demonstrated with a number of samples obtained from diverse ionization platforms where ESI and MALDI either failed or produced poor results. These favorable results are based primarily on improved selectivity for the compounds of interest rather than on more-universal ionization. Further expansion of matrices and solvents will likely provide better selectivity and more-universal ionization capabilities. For a wide range of compound classes, such as drugs and their metabolites, lipids, peptides, and proteins, the simple and robust ionization methods provide improved data quality with competitive and frequently improved sensitivity relative to ESI and MALDI. The new ionization processes have shown unique applications with instruments ranging from small portable systems to ultrahigh-resolution mass spectrometers, and have been used with LC, IMS, and advanced fragmentation technology such as electron transfer dissociation. Areas that will likely benefit the most from these low-cost ionization processes are those that are in dire need of simplicity, robustness, throughput, and field portability, such as biothreat detection, biomedical research, and eventually point-of-care diagnostics.
Acknowledgment
Any opinions, ï¬ndings, and conclusions or recommendations expressed in this material are those of the author and do not necessarily reï¬ect the views of the National Science Foundation. NSF CHE-1411376 and STTR Phase II 1556043 are kindly acknowledged.
References
- S. Trimpin, J. Am. Soc. Mass Spectrom. 27, 4–21 (2016).
- E.D. Inutan and S. Trimpin, Mol. Cell. Proteomics 12, 792–796 (2013).
- K. Hoang, M. Pophristic, A.J. Horan, M.V. Johnston, and C.N. McEwen, J. Am. Soc. Mass Spectrom.27, 1590–1596 (2016).
- S. Trimpin and E.D. Inutan, J. Am. Soc. Mass Spectrom. 24, 722–732 (2013).
- S. Trimpin, C.A. Lutomski, T.J. El-Baba, D.W. Woodall, C.D. Foley, C.D. Manly, B. Wang, C.W. Liu, B.M. Harless, R. Kumar, L.F. Imperial, and E.D. Inutan, Int. J. Mass Spectrom.377(SI), 532–545 (2015)
- V.S. Pagnotti, N.D. Chubatyi, and C.N. McEwen, Anal. Chem.83, 3981–3985 (2011).
- V.S. Pagnotti, N.D. Chubatyi, A.F. Harron, and C.N. McEwen, Anal. Chem.83, 6828–6832 (2012).
- M.A. Fenner, S. Chakrabarty, B. Wang, V.S. Pagnotti, K. Hoang, S. Trimpin, and C.N. McEwen, Anal. Chem.89, 4798–4802 (2017).
- S. Trimpin, B. Wang, E.D. Inutan, J. Li, C.B. Lietz, V.S. Pagnotti, A.F. Harron, D. Sardelis, and C.N. McEwen, J. Am. Soc. Mass Spectrom.23, 1644–1660 (2012).
- I.C. Lu, M. Pophristic, E.D. Inutan, R.G. McKay, C.N. McEwen, and S. Trimpin, Rapid Commun. Mass Spectrom.30, 2568–2572 (2016).
- I.C. Lu, E.A. Elia, W.J. Zhang, M. Pophristic, C.N. McEwen, and S. Trimpin, Anal. Methods DOI: 10.1039/C7AY00995J (2017).
- X. Liu, S.J. Valentine, M.D. Plasencia, S. Trimpin, S. Naylor, and D.E. Clemmer, J. Am. Soc. Mass Spectrom.18, 1249–1264 (2007).
- P.M. Peacock, W.J. Zhang, and S. Trimpin, Anal. Chem.89, 372−388 (2017).
- B. Wang and S. Trimpin, Anal. Chem.86, 1000–1006 (2014).
Sarah Trimpin is Professor of Chemistry at Wayne State University in Detroit, Michigan, and the co-founder and CEO of MSTM, LLC, in Newark, Delaware.
Proteoforms: A New Separation Dilemma
Fred E. Regnier and JinHee Kim
Proteins are the workhorses of cells, obviously requiring a high level of complexity; but how complex? Originally it was thought there would be a close relationship between the ~20,000 protein-coding genes in the human genome and the number of expressed proteins. Wrong! Through a variety of new methods including mass spectrometry (MS) sequencing it is now predicted there could be 250,000 to 1 million proteins in the human proteome (1).
But what does this have to do with chromatography? Liquid chromatography (LC) has played a pivotal role in discovering, identifying, and quantifying the components in living systems for more than a century. The question being explored here is whether that is likely to continue or if LC will become a historical footnote as the MS community suggests.
First, what is a proteoform? We know that during protein synthesis a protein-coding gene provides the blueprint for a family of closely related structural isoforms arising from small, regulated variations in their synthesis involving alternative splicing (2) and more than 200 types of post-translational modification (PTM) (3). This process can lead to a proteoform family of 100 members (4), many of which differ in biological function. The human genome gets more “bang” per protein-coding gene in this way. Smith and Kelleher proposed the name “proteoform” for these structural isoforms in 2013 (5).
An important issue is how these high levels of proteoform complexity were predicted. The idea arose from the identification of splice variant sites and large numbers of PTMs in peptides derived from trypsin digests, often supported by top-down sequence analysis of intact proteins by MS (6). The use of gas-phase ions to identify sites and types of modifications in the primary structure of a protein is of great value, but it must be accompanied by structure, function, and interaction partner (7,8) analysis of proteoforms in vivo. This combined analysis is needed because life occurs in an aqueous world.
There is the impression that the discovery, isolation, and characterization of proteins is highly evolved. Actually, fewer than 100,000 human proteins have probably been isolated and characterized. If the number of proteoforms predicted is accurate, less than half have been isolated and characterized. Protein isolation is inefficient. A breakthrough in separation technology is needed.
Protein peak capacities are no more than a few hundred in most forms of LC; suggesting peaks from a 1-million-component mixture could potentially bear 1000 proteins. Multidimensional separation methods are an obvious approach, but comprehensive structure analysis of a 200 × 200 fraction set to find proteoforms would be formidable. That has always been a problem. Obviously particle size, theoretical plates, and peak capacity tweaks will not solve this problem either. Moreover, structure selectivity of ion-exchange chromatography, hydrophobic interaction chromatography, reversed-phase LC, and immobilized metal affinity chromatography is poor. Proteins of completely different structure are coeluted.
Probing deeper, there is hope for this seemingly intractable problem. The fact that proteoforms arise from a single gene means they are cognates with multiple, identical structural features. A stationary phase that could recognize these shared features would make it possible to capture a proteoform family; theoretically reducing 1-million-component mixtures to fewer than 100 components in a single step. This possibility is of enormous significance. Species of no interest would be rejected while selected proteins would likely be structurally related with the exception of a few nonspecifically bound (NSB) proteins. In this scenario, the poor structure-specific selectivity of current LC columns would be an asset, fractionating family members based on other structural features. Moreover, top-down MS would identify structural differences and NSB proteins.
The big question is how to obtain such a magical, structure-selective stationary phase. Surprisingly, they already exist; an immobilized polyclonal antibody (pAb) interrogates multiple features (epitopes) of a protein, making it highly probable that features common to all proteoforms in a family would be recognized and selected. Family-specific monoclonal antibodies (mAbs) do the same, but only recognize a single shared epitope.
Production of a pAb targeting common proteome family epitopes can be achieved by using any member of an existing family as an immunogen. Thousands of pAbs are already available.
Proteins that have never been isolated present a larger problem. There is no family member to use as an immunogen. The new field of antibody-based proteomics (9–11) addresses this problem by using protein fragment libraries to obtain immunogens. The rationale is that the DNA sequence of a protein coding gene predicts 6–15 amino acid fragments of a protein family that when synthesized and attached to a large immunogen will sometimes produce antibodies that recognize common epitopes of the family.
Based on the need for fractionation in determining the structure and function of so many proteins, the future of LC in the life sciences seems bright, but with some enjoinments. Clearly, affinity selector acquisition and use is a major opportunity. The application of a family-selective phase in the first fractionation step would allow rejection of untargeted proteins while directing those of interest into higher-order fractionation steps. Fortunately, engineering and production of the requisite antibodies for implementing this approach to protein analysis is receiving increasing attention (9–11). Finally, new ways must be found to use affinity selectors in protein fractionation that circumvent covalent immobilization. The necessity to covalently bind ~20,000 different affinity selectors to achieve the goals noted above is inconceivable.
References
- T. Vacik and I. Raska, Protoplasma254, 1201–1206 (2017).
- D. Gawron, E. Ndah, K. Gevaert and P. Van Damme, Mol. Syst. Biol.12, 858 (2016).
- G. Qing, Q. Lu, Y. Xiong, L. Zhang, H. Wang, X. Li, X. Liang, and T. Sun, Adv. Mater.29, 1604670 (2017).
- E.A. Ponomarenko, E.V. Poverennaya, E.V. Ilgisonis, M.A. Pyatnitskiy, A.T. Kopylov, V.G. Zgoda, A.V. Lisitsa, and A.I. Archakov, Int. J. Anal. Chem.2016, 7436849 (2016).
- L.M. Smith and N.L. Kelleher, Nat. Methods10, 187 (2013).
- K.R. Durbin, L. Fornelli, R.T. Fellers, P.F. Doubleday, M. Narita, and N.L. Kelleher, J. Proteome Res. 15(3), 976–982 (2016).
- E.M. Phizicky and S. Fields, Microbiol Rev.59(1), 94–123 (1995).
- M.R. Arkin, Y. Tang, and J.A. Wells, Chem. Biol.21(9), 1102–14 (2014).
- M. Uhlen and F. and Ponte´n, Mol. Cell. Proteomics 4, 384–393 (2005).
- M. Uhlen, Mol. Cell. Proteomics6, 1455–1456 (2007).
- M. Uhlen, E. Bjorling, C. Agaton, C.A. Szigyarto, B. Amini, E. Andersen, A.C. Andersson, P. Angelidou, A. Asplund, and C. Asplund, Mol. Cell. Proteomics4, 1920–1932 (2005).
Fred E. Regnier and JinHee Kim are with Novilytic at the Kurz Purdue Technology Center (KPTC) in West Lafayette, Indiana.
The Complementarity of Vacuum Ultraviolet Spectroscopy and Mass Spectrometry for Gas Chromatography Detection
Kevin A. Schug
Vacuum ultraviolet absorption spectroscopy detection for gas chromatography (GC–VUV) was introduced in 2014 (1,2). The first generation of GC–VUV features a detector that simultaneously measures a full wavelength range of absorption for eluted compounds from 120 to 240 nm, where all chemical compounds absorb and have a unique absorption signature. This provides new qualitative analysis capabilities for GC, a tool that has been lacking multiple choices in that regard. Quantitative analysis is grounded in the simple concept of the Beer-Lambert law, where amounts of measured species are directly proportional to the magnitude of absorption. It is worth noting that the absorption intensity at 180 nm for benzene is about 10,000 times higher than its absorption at 254 nm. Because absorption is captured in the gas phase, spectra are much more highly featured than they are in solution phase, where interactions with solvent cause significant spectral broadening. Further, given classes of molecules have similar absorption features and the absorption intensity within a class of molecules is quite predictable. These are some of the aspects that make GC–VUV highly complementary to GC–mass spectrometry (GC–MS).
GC–MS has been the gold standard for combined qualitative and quantitative analysis of volatile and semivolatile compounds for many years. While some other GC detectors are highly selective, very few provide additional information beyond a retention time for compound identification. In that regard, GC–MS is not foolproof. While it has had many years to advance, and there are a wide variety of detector configurations available to choose from, GC–MS still has issues with differentiating isomeric compounds that have similar fragmentation patterns, especially if they are difficult to separate chromatographically. Additionally, the resolution of coeluted compounds requires sophisticated algorithms and software to tease apart temporal changes in complex fragment ion spectra. Many manufacturers and researchers have devised means for deconvolving overlapping peaks using GC–MS. The key is that there has to be some minimal temporal resolution of the species; perfectly coeluted components cannot be differentiated by these means.
GC–VUV excels in isomer differentiation and peak deconvolution. Electronic absorption of light in the 120–240 nm wavelength range probes the energy difference between the highest occupied molecular orbital (HOMO) and the lowest unoccupied molecular orbital (LUMO) of a molecule. The energy of this light is sufficient to excite electrons that reside in sigma-bonded, pi-bonded, and nonbonded (n) molecular orbitals. The high-resolution (±0.5 nm) gas-phase measurement enables underlying vibrational excitation features to be observed, superimposed on the electronic absorption features in the spectra. The difference in energies between the HOMO and LUMO are highly dependent on atom connectivity and molecular structure and thus, such a measurement is ideal for differentiating various kinds of isomers. While some consideration has to be given to the spectral similarity of coeluted species and their relative abundances (3), research has shown the technique to have exceptional power for deconvolution of coeluted species (4–6), even if there is no temporal resolution between them. The measured absorption spectra of overlapping species is simply a sum of their absorption features, scaled according to their relative abundances. Thus, the deconvolution algorithm easily accommodates a linear combination of scaled reference spectra, to project the contribution of individual species to any overlapping absorption event.
Isomer differentiation is perhaps the most intriguing complement of GC–VUV to GC–MS. The most recent example of the power of GC–VUV was its use for distinguishing a large set of new designer drugs (7). Automated deconvolution of entire GC-VUV chromatograms from complex mixtures, such as gasoline or Aroclor mixtures, is possible using an advanced technique called time interval deconvolution (TID) (8,9). TID can be used to rapidly speciate and classify components in a mixture based on the fact that classes of compounds have similar absorption features, as mentioned previously. When one searches an unknown signal against the VUV library, even if the compound is not in the library, the closest matches will be from the same compound class as the unknown. For GC–MS, though there can be some diagnostic fragments, only matching elemental formulas are generally returned from a search, so reported library matches could be more misleading in this regard.
From the quantitative standpoint, GC–VUV is about as sensitive as a standard GC–MS (quadrupole system) in scan mode (low- to mid-picogram amounts on column), but GC–VUV is also capable of calibrationless quantitation (10), by virtue of the highly reproducible absorption cross-section (that is, absorptivity) for molecules. This feature has only recently been explored in the context of real-world samples but could be a real time savings for GC analysis in future applications (11).
Some researchers have explored the operation of both VUV and MS detectors on one instrument. The best convention for this coupling in the future is probably going to be based on splitting column flow post-column, as opposed to placing the detectors in tandem. In tandem, the vacuum of the MS system could make it difficult to maintain sufficient peak residence time in the VUV detector; extracolumn band broadening effects are also a consideration. With a split flow, highly complementary qualitative and quantitative information can be obtained from a single separation. For many applications, the ability to collect information on both detectors would be a major advantage. It would significantly boost the confidence of identifying unknown species or targeting species of high interest or concern. Further, a second-generation VUV instrument is now available that features extended spectral ranges (up to 430 nm), higher temperatures (up to 420 °C), and improved detection limits to address challenging GC applications. In any case, the complementarity of GC–VUV and GC–MS cannot be denied. Each technique has advantages and limitations that balance the other. Certainly, the most desirable GC system in the future will contain both detectors to boost analytical performance and confidence in results.
Disclaimer
K.A. Schug is a member of the Scientific Advisory Board for VUV Analytics, Inc.
References
- K.A. Schug, I. Sawicki, D.D. Carlton Jr., H. Fan, H.M. McNair, J.P. Nimmo, P. Kroll, J. Smuts, P. Walsh, and D. Harrison, Anal. Chem.86, 8329–8335 (2014).
- I.C. Santos and K.A. Schug, J. Sep. Sci. 40, 138–151 (2017).
- J. Schenk, X. Mao, J. Smuts, P. Walsh, P. Kroll, and K.A. Schug, Anal. Chim. Acta945, 1–8 (2016).
- L. Bai, J. Smuts, P. Walsh, H. Fan, Z.L. Hildenbrand, D. Wong, D. Wetz, and K.A. Schug, J. Chromatogr. A1388, 244–250 (2015).
- H. Fan, J. Smuts, P. Walsh, and K.A. Schug, J. Chromatogr. A1389, 120–127 (2015).
- H. Fan, J. Smuts, L. Bai, P. Walsh, D.W. Armstrong, and K.A. Schug, Food Chem.194, 265–271 (2016).
- L. Skultety, P. Frycak, C. Qiu, J. Smuts, L. Shear-Laude, K. Lemr, J.X. Mao, P. Kroll, K.A. Schug, A. Szewczak, C. Vaught, I. Lurie, and V. Havlicek, Anal. Chim. Acta971, 55–67 (2017).
- P. Walsh, M. Garbalena, and K.A. Schug, Anal. Chem.88, 11130–11138 (2016).
- C. Qiu, J. Cochran, J. Smuts, P. Walsh, and K.A. Schug, J. Chromatogr. A 1490, 191–200 (2017).
- L. Bai, J. Smuts, C. Qiu, P. Walsh, H.M. McNair, and K.A. Schug, Anal. Chim. Acta953, 10–22 (2017).
- M. Zoccali, K.A. Schug, P. Walsh, J. Smuts, and L. Mondello, J. Chromatogr. A1497, 135–143 (2017).
Kevin A. Schug is the Shimadzu Distinguished Professor of Analytical Chemistry in the Department of Chemistry and Biochemistry at The University of Texas at Arlington in Arlington, Texas.
Separations: A Way Forward
A.M. Stalcup
The analytical separations community has really made tremendous advances in the last couple of decades to satisfy the demands for higher throughput and address the increasing demands presented by the complexities of various “omics” samples (proteomics, glycomics, metabolomics, and so forth). These advances have been largely accomplished through a collective re-envisioning of separation platforms (for example, solid-phase microextraction, microfluidics, and capillary electrophoresis), mobile phases (such as supercritical fluids and enhanced fluidity), chromatographic media (for example, chiral, smaller particles, core-shell particles, monoliths, and polymerized ionic liquids), and practice (such as slip flow, ultrahigh pressures in high performance liquid chromatography [HPLC], and ultrahigh-temperature gas chromatography [GC] and HPLC). As a result, a very sophisticated material science has emerged and it is astounding that the range of analytes that can now be resolved by the separations community extends from ions to small molecules to polymers, biopolymers, cell organelles, and even cells.
The paradox is that one of the biggest challenges facing separation science is that many of our academic colleagues consider what separations scientists do as merely a necessary evil in support of “real” science and either witchcraft or trivial, while our industrial colleagues decry the declining chromatographic expertise in some of our graduates. Some of this generally low esteem (it is now more than 65 years since Martin and Synge’s Nobel prize and one cannot help but feel occasionally that some scientists would be just as happy if separations were retired) for separation science by our academic colleagues is perhaps historical as Twsett’s original work was ignored or ridiculed by his contemporaries. These attitudes may also have given rise to historically low funding for fundamental separations science research. Nevertheless, this “familiarity breeds contempt” quality arguably impacts analytical chemistry in other areas as well (for example, perhaps spectroscopy and electrochemistry). Hence, the analytical separations community might be advised to adopt strategies used by more highly regarded analytical techniques such as mass spectrometry (MS) to boost stature.
While MS is one of the oldest analytical techniques (that is, 1913: isotopes of neon), the last couple of decades have seen an incredible evolution in instrumentation and methodologies to tackle emerging analytical problems previously beyond the scope of contemporaneously available instrumentation. This was in part enabled by the coherence of the MS community in coupling advances in computer science, data management, and electronics to new interfaces and discriminatory power. However, it might also be argued that another contributory factor is that the MS community never forgot they were chemists first. This is clear from the early groundbreaking work by McLafferty relating electron impact ionization fragmentation to chemical structure (1) right through more recent work looking at hydrogen-deuterium exchange mass spectrometry and reexamination of the role of the matrix-assisted laser desorption-ionization (MALDI) matrix in ionization (2).
After a couple decades of engineering faster, better separations, it may be time for the separation science community to remember their chemical roots and bring a little supra-analytical separation science (SaSS) to the table, exploiting the dynamic chemical interactions between solute, mobile phase, and stationary phase that mask a wealth of inherent molecular information about interactions. The increasing success of chemically informed predictive retention models (for example, linear solvation energy relationships) are now approaching levels where separation science can provide a powerful enabling technology for predictions of performance and conditions to address emerging challenges (for example, pharmaceutical formulations) that were never previously considered amenable to separations-based approaches.
Finally, I want to heartily congratulate the LCGC team for LCGC North America’s 35th year of publishing! I originally encountered LCGC as a graduate student at Georgetown University. As a novice just finding my professional legs, I appreciated the accessibility of the scientific articles and the announcements of conferences, awards, and so on. Often, the first articles I read were the regular troubleshooting columns by John Dolan and John Hinshaw because the practical advice provided was particularly valuable in sorting out the mysteries of filters, ferrules, and connections, especially in academic labs where the relevant technical expertise was often in short supply. At the time, LCGC was one of the few places to find that kind of help and the spirit of open sharing of hard-earned information and a sense of a common purpose (that is, better, faster, separations) helped shape my enduring professional outlook! Over the course of my academic career, I have encouraged students to take advantage of the free subscription and used some of the material in my classes. Fortunately, I was able to leave my extensive collection of back issues when I moved to Ireland (LCGC’s reach is truly global) now that the articles are readily accessible on-line. Well done and thank you!
References
- F.W. McLafferty, Anal. Chem. 31, 82–87 (1959).
- J.R. Engen, Anal. Chem.81, 7870–7875 (2009).
A.M. Stalcup is with the School of Chemical Sciences at Dublin City University in Dublin, Ireland.
Having It All, and with Any Mass Spectrometer
Richard D. Smith
The challenges in the analysis of complex biological and environmental samples are open-ended: We want from our separations (and often truly need) more resolution, greater peak capacity, higher reproducibility, faster speed, and the ability to work with smaller and smaller samples. For detection, and specifically with mass spectrometry (MS), we want greater measurement sensitivity, wider dynamic range, better interface robustness with the separation, more effective compound identification, and improved precision and accuracy of quantification.
While significant progress has been made at individually addressing each of these desires, advances that combine these attributes have been far less common, and approaches that address most (or all) of these desires have been elusive. Such a convergence of capabilities would have profound impacts in broad areas, ranging from biological research to clinical practice. For example, this combination would enable not only much greater throughput, but also much better effectiveness in areas such as proteomics and metabolomics measurements.
I am confident that such analytical advances are now on the horizon, and that they will be broadly disruptive in areas where the best approaches currently involve the combination of a separation approach, particularly liquid chromatography (LC) with MS. Further, I believe these advances will be based upon new developments related to ion mobility (IM) separations (1).
Recent years have seen not only the increasing use of IM with MS, but also a proliferation of IM formats with quite different attributes, and their growing mainstream commercial availability (1). At present, the most broadly useful platforms insert a drift tube or traveling-wave IM stage between the conventional separation (LC) and MS systems, most notably an inherently fast time-of-flight (TOF) MS system for broad (that is, nontargeted) analyses. Despite this development, it really is early days for IM-MS; a phase typically marked by much interest and exploration of possible applications. However, to this point there have been only the earliest hints of a possible transition to its wide and routine use.
IM has long been recognized as having many attractive features. It is extremely fast, with separations typically on a millisecond timescale. Since separations take place in a gas using electric fields, IM avoids analyte ion contact with surfaces and can achieve levels of reproducibility not feasible with chromatography. IM-MS-derived collision cross sections provide important information on analyte ion size and shape. Because IM is conducted after sample ionization, it is a natural adjunct to MS with insertion between the ionization and m/z analysis stages, generally requiring only modest increases in platform complexity. As a result, recent advances in MS ion utilization efficiency can be used, and it thus becomes practical to work with far smaller sample sizes than is generally feasible with conventional condensed phase separations. Finally, IM is broadly applicable, in many cases using nitrogen as a “pseudo-stationary phase” for applications that can span fields such as proteomics, metabolomics, lipidomics, and glycomics-and even multiplexing such measurements in a single run.
Despite these attributes, IM has some well-recognized deficiencies. Most significant is its relatively low separation (or resolving) power and achievable peak capacities, with both typically under 100. And while greater resolving powers and peak capacities (for example, several hundred) have been achieved by individual labs, these advances have only been made in conjunction with some combination of greatly reduced sensitivity (or ion losses) and substantially reduced speed. Related issues involve limitations to the analyte ion mobility range covered, the need to slowly “scan” mobilities for some IM formats, and the restriction of the size of ion populations that can be injected for a separation because of ion volume and space charge limitations (as in drift tube IM measurements), which result in very limited signal-to-noise ratios or the common practice of summing data for long time periods.
However, I believe disruptive changes are on the horizon based on recent developments in IM separations conducted in structures for lossless ion manipulations (SLIM) that can address all these deficiencies simultaneously (2–11). The SLIM approach represents a dramatic departure in how ions in gases are manipulated, allowing for the creation of devices using previously impossible sets of complex and integrated (but also efficient) ion manipulations. SLIM are literally constructed from electric fields: SLIM use large electrode arrays patterned on two planar surfaces to create radio frequency and direct current ion confining fields. Additional superimposed electric fields enable not only IM separations, but also the ability to efficiently transmit ions through turns, switch them between paths, and store them over long times (that is, hours) without losses (2)!
The significance of these advances was greatly amplified by SLIM utilizing traveling waves (TW). Such IM separations are based on the mobility-dependent ability of ions to “keep up” with the TW (3). The relatively low voltages needed for TW removed the pathlength limitation and enabled the design of long, but compact serpentine IM paths (4). This design improvement considerably amplified the achievable IM resolution, avoiding the increasingly high voltages necessary in drift tube IM, which limits their maximum practical pathlength to only ~1 m. A 13-m SLIM IM path design provided resolution more than five times greater than that achieved using the best drift tube IM alternative, enabling baseline resolution of structurally similar and previously challenging isomers (5-7).
Building on this advance, we recently developed a SLIM serpentine ultralong path with extended routing (SUPER) platform for even higher resolution IM in conjunction with MS (8). This SLIM SUPER IM-MS utilizes a 13-m serpentine long-path drift length with an “ion switch” at the end to route ions either to the MS system or back to the beginning of the serpentine path. This “multipass” SLIM SUPER IM-MS platform provides much longer IM drift paths while still maintaining essentially lossless ion transmission. Recent developments have also established the feasibility of creating multilevel three-dimensional (3D) SLIM for constructing compact ultralong IM paths (9).
However, there are a few other somewhat subtle but crucially important issues. These are related to gradual IM peak dispersion (because of diffusion and other factors for ultralong separation paths) and the maximum ion population sizes that can be injected for a single IM separation. These issues result in limitations on essentially all key performance metrics, including achievable resolution, mobility range, detection dynamic range, and signal-to-noise ratios.
It turns out that these two remaining issues can both be addressed by a new SLIM capability allowing temporal and spatial compression or “squeezing” of any ion distribution, including complete IM separations, without losses of IM resolution and to an extent limited only by the physics of ion space charge (10). This compression ratio ion mobility programming (CRIMP) process provides greater signal intensities and reduced peak widths, thus optimizing MS detection, and enabling the use of much longer pathlengths. In SLIM, ions are naturally distributed in “bins” created by the TW, with an IM peak generally spanning many bins. With CRIMP, a “traveling trap” (TT) region that utilizes a normal TW is interfaced with a “stuttering trap” (ST) region in which the TW is periodically paused, allowing ions from multiple TW bins in the TT region to merge into a single bin in the ST region as they move through the interface between the two regions. The repetition of this process thus spatially compresses any incoming ion population in a lossless fashion. Dynamic switching of the ST region from a stuttering TW mode back to the normal TT mode of operation “locks in” the spatial compression, allowing for continuation of the IM separation, albeit with narrowed peak widths and increased peak intensities. We recently illustrated that CRIMP with SLIM greatly expands capabilities for both ion accumulation and ion injection (11). It has also enabled both in a fashion that is fully compatible with IM separations. These developments have allowed more than 5 billion ions to be accumulated, providing more than a 100-fold increase in IM-MS sensitivity compared to the best results achieved previously (11).
In conclusion, the conflicting challenges posed by our desired separation and detection improvements now seem quite surmountable: SLIM-based IM-MS appears to provide a straightforward path to broadly effective, and likely disruptive, new capabilities with impacts across a broad range of applications. Time will tell!
References
- B.C. Bohrer, S.I. Merenbloom, S.L. Koeniger, A.E. Hilderbrand, and D.E. Clemmer, Annu. Rev. Anal. Chem. 1, 293–327 (2008).
- X. Zhang, S.V.B. Garimella, S.A. Prost, I.K. Webb, T.-C. Chen, K. Tang, A.V. Tolmachev, R.V. Norheim, E.S. Baker, G.A. Anderson, Y.M. Ibrahim, and R.D. Smith, Anal.Chem. 87, 6010–6016 (2015).
- A.M. Hamid, Y.M. Ibrahim, S.V.B. Garimella, I.K. Webb, L. Deng, T.-C. Chen, G.A. Anderson, S.A. Prost, R.V. Norheim, A.V. Tolmachev, and R.D. Smith, Anal. Chem.87(11), 301–11,308 (2015).
- L. Deng, Y.M. Ibrahim, A.M. Hamid, S.V.B. Garimella, I.K. Webb, X. Zheng, S.A. Prost, J.A. Sandoval, R.V. Norheim, G.A. Anderson, A.V. Tolmachev, E.S. Baker, and R.D. Smith, Anal. Chem.88, 8957–8964 (2016).
- L. Deng, Y.M. Ibrahim, E.S. Baker, N.A. Aly, A.M. Hamid, X. Zhang, X. Zheng, S.V. B. Garimella, I.K. Webb, S.A. Prost, J.A. Sandoval, R.V. Norheim, G.A. Anderson, A.V. Tolmachev, and R.D. Smith, ChemistrySelect 1, 2396–2399 (2016).
- R. Wojcik, I.K. Webb, L. Deng, S.V.B. Garimella, S.A. Prost, Y.M. Ibrahim, E.S. Baker, and R.D. Smith, Int. J. Mol. Sci. 18, 183 (2017).
- Y.M. Ibrahim, A.M. Hamid, L. Deng, S.V.B. Garimella, I.K. Webb, E.S. Baker, and R.D. Smith, Analyst142, 1010–1021 (2017).
- L. Deng, I.K. Webb, S.V.B. Garimella, A.M. Hamid, X. Zheng, R.V. Norheim, S.A. Prost, G.A. Anderson, J.A. Sandoval, E.S. Baker, Y.M. Ibrahim, and R.D. Smith, Anal. Chem. 89, 4628–4634 (2017).
- Y.M. Ibrahim, A.M. Hamid, J.T. Cox, S.V.B. Garimella, and R.D. Smith, Anal. Chem.89, 1972–1977 (2017).
- S.V.B. Garimella, A.M. Hamid, L. Deng, Y.M. Ibrahim, I.K. Webb, E.S. Baker, S.A. Prost, R.V. Norheim, G.A. Anderson, and R.D. Smith, Anal. Chem.88, 11877–11885 (2016).
- L. Deng, S.V.B. Garimella, A.M. Hamid, I.K. Webb, I.K. Attah, R.V. Norheim, S.A. Prost, X. Zheng, J.A. Sandoval, E.S. Baker, Y.M. Ibrahim, and R.D. Smith, Anal. Chem.89, 6432–6439 (2017).
Richard D. Smith is with the Biological Sciences Division at Pacific Northwest National Laboratory in Richland, Washington.
Miniaturizing Columns and Instruments in Liquid Chromatography
James P. Grinias and Glenn A. Kresge
As electronic devices and computers have continued to shrink in size over the past few decades, many analytical methods have as well, including liquid chromatography (LC). Although 4.6-mm and 2.1-mm i.d. columns still dominate the field of LC, smaller diameter columns have found utility in a number of applications, especially for the analysis of small volumes of complex biological samples by LC–multiple-stage mass spectrometry (MSn) (1). When using these columns with internal diameters of 5–500 µm, considerations must be made in terms of the column format and the type of stationary-phase support (2). Capillaries (usually made of fused silica) and microfabricated devices containing microfluidic channels are the two main formats that can be implemented. By far, capillaries are the more common of the two, with many commercial vendors offering a wide selection of capillary-scale (or “nano”) LC columns. Microfluidic LC columns are not as widely available because their fabrication and preparation process can be far more labor intensive (3,4). Despite difficult production, the integration of connections between the pump, column, and detector into a single device can simplify column installation in commercial microfluidic LC systems.
In both formats, the stationary phase is typically bonded either directly to the column wall, to particles, or to a monolithic structure. Open-tubular columns promise extremely high efficiencies, especially at very small diameters, but limited sample capacity can sometimes make detection sensitivity of low-concentration analytes an issue (5). For particles, many that have been used in analytical-scale columns can also be packed into smaller diameter channels. Recent research has correlated packing techniques to both bed structure and chromatographic performance having led to the preparation of very high efficiency columns (1,6).
Submicrometer particles in this format have shown phenomenal performance, especially when interactions between the bonded and mobile phases promote slip-flow conditions (7). Particle-packed microfluidic LC columns usually have lower efficiencies than cylindrical capillaries because of differences in their cross-sectional area, difficulties associated with fabricating circular channels, and lower achievable packing pressures that affect bed porosity (8). Monoliths provide an integrated structure that can better fill these different cross sections and show promise for use in microfluidic LC, especially since the support can be localized to specific areas of the device where separation is desired (9). Microfabrication of the actual column structure has also been demonstrated through the use of pillar-array columns, which can be designed to exact specifications that optimize chromatographic performance (10). This technology only recently became available commercially, and while it is still more expensive compared to other column formats, the use of these microfabricated columns likely will only grow as the price decreases. Potential ways to reduce fabrication costs include using an embossing process from a microfabricated master (11) or three-dimensional (3D)-printing (12), although a reduction in defects and improvements to feature resolution will be needed to achieve the same efficiency observed in silicon-based devices.
The small-volume columns described thus far still require large instrumentation for both flow generation and detection (13). However, new technologies have started to enable the miniaturization of the entire LC system and this trend will likely continue. Smaller pumps that are capable of achieving ultrahigh pressure flow in the nanoliter- to microliter-per-minute range show promise in not only reducing the pump footprint, but also provide opportunities for developing new, fully portable liquid chromatographs (14). Here, either traditional piston or electroosmotic pumping can be utilized to generate the flow needed for capillary and microfluidic LC columns. Decreases in the size of optical detectors have also been reported, mainly through improvements in the design and operation of light-emitting diode (LED) sources, with good sensitivity for on-column detection despite the reduced pathlength compared to standard flow cells (15). Contactless conductivity (16) and electrochemical (17) detectors can also be implemented in smaller systems or even integrated into a microfluidic device that also contains a separation column, although the number of analyte classes that respond to these detectors is smaller than with optical detection. Mass spectrometry, the most important detection method for capillary-scale separations, has a number of challenges related to miniaturization, including the size of the vacuum pumping system and mass analyzer. Advances toward reducing the size of these components has led to both small benchtop and portable MS detectors (18). Improving the mass resolution of these systems will be the biggest challenge to matching the performance of the more standard MS systems used in complex biological analyses. No matter which of the detectors is used, data acquisition and instrument control interfaces are also needed. As both smartphones and single-board miniaturized computers become more common and continue to grow in computing power, replacing large desktop systems with much smaller setups for data collection and processing will also help reduce system size (19).
With column and instrument miniaturization, several aspects of the method must be improved compared to standard techniques to achieve wide use. Although there are several recent reports of exceptional chromatographic efficiency with capillary columns, commercial systems must be designed to ensure that any performance gains are not lost to instrumental band broadening. Smaller detectors must still provide adequate detection limits for the samples being analyzed, which can be difficult because injected volumes are typically well below 1 µL. Perhaps most importantly, new miniaturized liquid chromatographs must be as robust (if not more so) and user-friendly as standard size instruments to encourage their adoption for routine analysis. As further advances in column and instrument technology are made to improve chromatographic efficiency and reduce system size, enhanced separation performance at the nanoliter scale will be both easier and more affordable to attain.
References
- L.E. Blue, E.G. Franklin, J.M. Godinho, J.P. Grinias, K.M. Grinias, D.B. Lunn, and S.M. Moore, J. Chromatogr. A, in press (2017).
- G. Desmet and S. Eeltink, Anal. Chem.85, 543–556 (2013).
- J.P. Kutter, J. Chromatogr. A1221, 72–82 (2012).
- J.P. Grinias and R.T. Kennedy, TrAC Trends Anal. Chem. 81, 110–117 (2016).
- D.A. Collins, E.P. Nesterenko, and B. Paull, Analyst139, 1292–1302 (2014).
- J.M. Godinho, A.E. Reising, U. Tallarek, and J.W. Jorgenson, J. Chromatogr. A 1462, 165–169 (2016).
- B.A. Rogers, Z. Wu, B. Wei, X. Zhang, X. Cao, O. Alabi, and M.J. Wirth, Anal. Chem.87, 2520–2526 (2015).
- S. Khirevich, A. Höltzel, D. Hlushkou, and U. Tallarek, Anal. Chem.79, 9340–9349 (2007).
- F. Svec and Y. Lv, Anal. Chem.87, 250–273 (2015).
- J. Eijkel, Lab Chip7, 815–817 (2007).
- K. Tsougeni, K. Ellinas, H. Archontaki, and E. Gogolides, J. Micromechanics Microengineering25, 15005 (2015).
- S. Waheed, J.M. Cabot, N.P. Macdonald, T. Lewis, R.M. Guijt, B. Paull, and M.C. Breadmore, Lab Chip16, 1993–2013 (2016).
- J. Šesták, D. Moravcová, and V. Kahle, J. Chromatogr. A1421, 2–17 (2015).
- S. Sharma, L.T. Tolley, H.D. Tolley, A. Plistil, S.D. Stearns, and M.L. Lee, J. Chromatogr. A1421, 38–47 (2015).
- M. Macka, T. Piasecki, and P.K. Dasgupta, Annu. Rev. Anal. Chem.7, 183–207 (2014).
- M. Pumera, Talanta74, 358–364 (2007).
- J. Wang, Talanta56, 223–231 (2002).
- Z. Ouyang, and R.G. Cooks, Annu. Rev. Anal. Chem. 2, 187–214 (2009).
- P.L. Urban, Analyst 140, 963–975 (2015).
James P. Grinias is an assistant professor in the Department of Chemistry and Biochemistry at Rowan University in Glassboro, New Jersey. Glenn A. Kresge is a is a fourth-year student majoring in biochemistry at Rowan University.
Life in the Fast Lane with High-Throughput Separations
Robert T. Kennedy
The field of separations can benefit by addressing challenges of complex samples, miniaturization, and faster assays. In this article, I consider the issue of speed. Fast separations mean different things to different scientists so it is worth considering these different points of view. Fast can mean rapid turnaround for a specific assay, such as one that may be used in an emergency clinical setting or process analytical chemistry, where a known chemical is to be measured and action will be taken based on the result. Or fast can mean providing rapid information but on ever-changing targets. A good example is research and development (R&D) in the pharmaceutical industry. As new compounds become of interest, assays need to be quickly developed and then used for thousands of samples. Fast can also mean high-throughput where 103–106 assays must be performed in a short period of time. Examples include genome sequencing, screening reactions, and screening libraries for active compounds (such as drug candidates).
Separations methods are often discarded, or never considered, when speed of analysis is truly critical. Sensors, fluorescence assays, and ambient ionization methods with mass spectrometry (MS) have become preferred methods for such assays. This trend is apparent despite the fact that otherwise separations are often the “go-to method” because of the substantial improvement in data quality from using separations coupled to spectroscopy, MS, or electrochemistry. Reasons for overlooking separations when speed and throughput are needed include traditionally slow analysis times, the need for sample preparation, complexity of instrument maintenance, and lack of options for parallel operation (at least for chromatography). Overcoming these limitations to enable rapid and high-throughput separations assays could revolutionize many fields including chemical synthesis, biological sensing, diagnostics, and drug discovery.
Research in the past few decades has greatly advanced the speed of the actual separation. Gas chromatography (GC), high performance liquid chromatography (HPLC), and capillary electrophoresis (CE) with subsecond separation times have been demonstrated. Although peak capacity is often lost when going to such extreme speeds, it is possible to achieve a respectable peak capacity of 50 with impressive separations times less than 10 s, especially using CE and GC. These results show that it is indeed feasible to achieve high-quality separations in times that compete with other “fast” analytical techniques.
Looking forward, it is apparent that numerous hurdles must be overcome to improve the applicability, utility, and accessibility of this speed. Important issues to address include time for method development and sample preparation, developing injectors and sample manipulation that can keep pace with the separation, reequilibration times (chromatography columns), stability (for thousands of assays), and detectors that can record spectra under the conditions of the fast assays. In particular, it would be exceptionally powerful to have mass spectrometers that can collect spectra on the millisecond-wide peaks that can be achieved with fast separations. As discussed below, research groups working on these issues have been successful in bringing the power of fast separations to bear on both old and new problems.
Analytical chemists in pharmaceutical R&D are regularly presented with new drug candidates that need assays. Chromatography method development time can be the bottleneck in providing the analytical information needed in the fast-paced world of pharmaceutical R&D. Pharmaceutical companies have invested in methods that allow rapid selection of the proper column or conditions for a given separations problem. At the 45th International Symposium on High Performance Liquid Phase Separations and Related Techniques (HPLC 2017) in Prague, Czech Republic, Kelly Zhang of Genentech presented a novel two-dimensional (2D) platform that effectively eliminated the need for method development for many of the common problems faced in the pharmaceutical industry, generating a “fast” method for that environment (1).
Chemical synthesis research increasingly relies on high-throughput experimentation to discover new reactions and catalysts and to optimize reactions. A team at Merck has been active in integrating chromatography into this workflow (2,3). Recognizing that injections and sample handling can be limiting for high-throughput, they used the multiple injection in a single experimental run (MISER) technique to allow ~10-s cycle times. This technique has been used to perform more than 1500 different chemical synthesis experiments in a single day with HPLC data for each experiment. Further improvements in injection methods are needed to further enhance the throughput of this approach.
High-throughput screening in drug discovery is dominated by fluorescence assays; however, the power of a separation can often be useful, as illustrated by the success of the lab-on-chip systems for screening (4). Although microchip electrophoresis can achieve subsecond separations, rapidly introducing new samples to a chip limits actual throughput. We have recently demonstrated that droplet microfluidics may be a useful tool for enabling fast sample manipulation and injection, achieving 1400 assays in 46 min for an enzyme screen (5).
Protein biochemistry routinely uses western blot for assays. Although fast protein separations by microchip CE has been known for two decades, only recently have groups considered the other aspects needed for fast western blots and integrated them with fast separation (6). Achievements in this area are pointing toward high-throughput western blots with single-cell sensitivity for protein analysis.
It is apparent that achieving useful, rapid separations requires a holistic view that considers all steps of the analysis, not just the actual separation step. Decreasing injection time and eliminating sample preparation are examples of actions that are needed to enable truly fast and high-throughput separations. The examples above show that microfluidics is a potential route for overcoming some of the “extracolumn” limitations of separations speed and throughput.
Achieving rapid and high-throughput separations will add a new tool to the analyst’s armamentarium. Imagine the utility of a chromatograph that required no sample preparation and no method optimization but was “smart” enough to achieve these front-end tasks quickly and efficiently. Fast assays could be used more routinely for clinical diagnostics and threat detection. Integration of fast separations with sampling would allow biological sensing and process monitoring. Faster, and truly high-throughput separations, would be an important new tool in chemical biology, catalysis discovery, and drug discovery by allowing high-throughput screening.
References
- K. Zhang, “Multiplexed mLC-nLC for Comprehensive Impurity Profiling: A Method Development ‘Free’ Platform,” presented at the 45th International Symposium on High Performance Liquid Phase Separations and Related Techniques (HPLC 2017), Prague, Czech Republic, 2017.
- K. Zawatzky, C.L. Barhate, E.L. Regalado, B.F. Mann, N. Marshall, J.C. Moore, and C.J. Welch, J. Chromatogr. A 1499, 211–216 (2017).
- A. Buitrago Santanilla, E.L. Regalado, T. Pereira, M. Shevlin, K. Bateman, L.C. Campeau, J. Schneeweis, S. Berritt, Z.C. Shi, P. Nantermet, Y. Liu, R. Helmy, C.J. Welch, P. Vachal, I.W. Davies, T. Cernak, and S.D. Dreher, Science347(6217), 49–53 (2015).
- A. Card, C. Caldwell, H. Min, B. Lokchander, X. Hualin, S. Sciabola, A.V. Kamath, S.L. Clugston, W.R. Tschantz, W. Leyu, and D.J. Moshinsky, J. Biomol. Screen14(1), 31–42 (2009).
- E.D. Guetschow, D.J. Steyer, and R.T. Kennedy, Anal. Chem.86(20), 10373–9 (2014).
- A.J. Hughes and A.E. Herr, Proc. Natl. Acad. Sci. U.S.A.109(52), 21450–5 (2012).
Robert T. Kennedy is the chair of the Chemistry Department, a Hobart Willard Distinguished University professor, and a professor of chemistry and pharmacology at the University of Michigan in Ann Arbor, Michigan.
Haven’t We Been Doing Multidimensional GC Analysis Forever? So, What Is New?
Philip J. Marriott and Yong Foo Wong
Multidimensional analysis (MDA) certainly has been done for a long time! Many people are, to a lesser or greater degree, experienced in MDA. By MDA, we mean hyphenated chemical analysis combining two distinct techniques that themselves are bona fide analysis methods. The most recognizable MDA technique is gas chromatography–mass spectrometry (GC–MS)-combining dimensions of GC, which generates a sequence of time-resolved components and potentially constitutes molecular speciation, with a mass spectrum that provides some measure of molecular specificity by virtue of the mass fragmentation pattern of a molecule. By all accounts, GC–MS operates reliably, reproducibly, and sensitively for components detected by MS, for a sample that is resolved into chemical components by GC. Without further information, GC lacks molecular specificity, since it just gives the recognized peak response to each compound in a sample. If we can assign each response to a specific compound, then GC provides reliable molecular information. Thus, GC–MS is used as both a screening and target analysis method-we get a snapshot of the total sample or we can analyze a subset of compounds.
This approach is acceptable, but there are significant provisos. Single resolved components allow MS-to the best of its ability-to give an indication of identity and amount of the compound. But two basic problems exist: MS may be incapable of correctly identifying compounds, and for samples with many components and considerable overlaps the mass spectrum is a composite result of all these overlaps. The first problem is a basic limitation of the mass spectrum; many compounds have similar MS data (for example, isomers) so they lack specificity. In this case, a compound’s GC retention index might be used as a further filter for identification. For the latter, deconvolution or MS/MS operation might reveal the presence of a given compound, where for MS/MS a specific ratio of precursor and product ion might be sufficient to confirm a compound.
Another option exists for MDA and it involves multidimensionality of separation. Described soon after the introduction of GC, and best implemented by microfluidic Deans switching, today multidimensional GC (MDGC) is well-established, with a number of manufacturers offering their own version of devices, supported by software method development (1). There is essentially only one driver for which MDGC is required, which is to resolve regions that are unresolved on a first column (first dimension [1D]) by transfer (heart-cut) to a second column (second dimension [2D]), which logically will be a different separation mechanism-for GC this need for a different separation mechanism is translated into columns of different polarity. An obvious key application is the analysis of chiral compounds, where unresolved enantiomers on an achiral column are transferred to a suitable enantioselective 2D column. In this case, methods are usually based on classical-length 1D and 2D columns, so elution on the latter column is not fast and normally only a few selected regions are cut to the 2D column (2).
This approach has an obvious limitation. For a sample with essentially overlapping components over its full elution range, it would be desirable to apply the advantage of the two-column separation to the total sample. In this case, no decision needs to be made regarding transfer of a few limited regions; sampling should be conducted continuously. Giddings proposed a solution: to sample across the 1D separation, but ensure that the sampling process does not reduce the resolution that had already been achieved on the 1D column. The logical outcome is that the 2D elution should be faster than the elution duration (width) of a 1D peak; the 2D column should be short enough to complete the analysis in the same time as 1D is sampled. This approach was put into practice by Phillips, who is credited with the development of comprehensive 2D-GC (GC×GC) (3). Although most of the proponents of GC×GC study samples with high complexity, and demonstrate exceptionally high resolution across the total elution range (4–7), the uptake of GC×GC is far less than one might predict based on the general need to analyze these sorts of samples. One unique and perhaps less exploited property of GC×GC is that the resulting 2D space, comprising the 1D and 2D elution times, is a very precise chemical property “map.” Thus a compound will be located in a specific position in the 2D plot as a result of its physicochemical properties-boiling point, and specific interaction mechanisms with each stationary phase, under the prevailing temperature conditions. Therefore, it is often stated that GC×GC provides “structure” in the 2D space, such that compounds are located in zones that reflect their related properties. On a low-polarity 2D column, alkanes will be eluted latest; with a high-polarity 2D phase alkanes will be eluted earliest on the 2D column. Recently, it has been proposed that pressure tuning of a 1D column ensemble (dual columns)-a process that effectively alters the apparent polarity of the 1D separation-allows peaks in a sample to alter their relative position, and might be useful in tuning the 2D orthogonality of the experiment and simplify method development (8).
Multidimensionality has been further extended to related designs for multiple separation dimensions, with multiple columns interfaced in a facile manner, various flow switching devices and cryotrapping procedures, permitting an array of new operational procedures in advanced MDA. These include a comprehensive three-dimensional (3D) experiment (GC×GC×GC) (9,10), and a hybrid GC×GC–GC method, which combines GC×GC with heart-cutting and then elution on a third column (11). This approach was recently applied in a four-column GC×GC–GC–GC experiment, to study the separation of E/Z and R/S isomers of oximes; each isomer was subjected to chemical transformation on a third column, and then their isomeric abundance was measured on a fourth column (12). Such novel hybrid GC designs and applications cannot be conducted in a conventional GC arrangement. These multidimensional advances have moved beyond conceptualization to implementation and optimization, to benefit chromatographers in ways not possible in 1D and 2D GC methods. Unquestionably, very complex samples can be better resolved (ideally with solutes completely resolved) using these advanced MDA techniques, with more information extracted to meet analysts’ objectives.
References
- K.M. Sharif, S.-T. Chin, C. Kulsing, and P.J. Marriott, TrAC Trends Anal. Chem.82, 35–54 (2016).
- Y.F. Wong, R.N. West, S.-T. Chin, and P.J. Marriott, J. Chromatogr. A1406, 307−315 (2015).
- Z. Liu and J.B. Phillips, J. Chromatogr. Sci.29, 227–231 (1991).
- B. Mitrevski, K. Kouremenos, and P.J. Marriott, Bioanalysis1, 367–391 (2009).
- P.J. Marriott, S.-T. Chin, B. Maikhunthod, H.-G. Schmarr, and S. Bieri, TrAC Trends Anal. Chem.34, 1–21 (2012).
- S.-T. Chin and P.J. Marriott, Chem. Commun. 50, 8819–8833 (2014).
- Y. Nolvachai, C. Kulsing, and P.J. Marriott, Crit. Rev. Environ. Sci. Technol.45, 2135–2173 (2015).
- K.M. Sharif, C. Kulsing, and P.J. Marriott, Anal. Chem.88, 9087–9094 (2016).
- N.E. Watson, H.D. Bahaghighat, K. Cui, and R.E. Synovec, Anal. Chem.89, 1793−1800 (2017).
- N.E. Watson, S.E. Prebihalo, and R.E. Synovec, Anal. Chim. Acta, in press, DOI:
https://doi.org/10.1016/j.aca.2017.06.017 (2017).
- B. Mitrevski and P.J. Marriott, Anal. Chem. 84, 4837−4843 (2012).
- Y.F. Wong, C. Kulsing, and P.J. Marriott, Anal. Chem.89, 5620−5628 (2017).
Philip J. Marriott and Yong Foo Wong are with the Australian Centre for Research on Separation Science in the School of Chemistry at Monash University in Victoria, Australia.
Complex Matrices Analysis by Direct-Immersion SPME with Matrix-Compatible Coatings: A New Approach Compatible with Automation
Janusz Pawliszyn and Emanuela Gionfriddo
The analysis of complex matrices always poses the ultimate challenge to the analytical chemistry community with regards to targeted and untargeted analyses. The major reason being sample preparation and separation strategies always seek to guarantee “cleaner extracts” that provide enough analyte enrichment while ensuring negligible instrument contamination and matrix effects. In the process, to date, sample preparation approaches for the analysis of complex matrices are characterized by multiple and tedious steps that most often require larger solvent volumes, with low throughput.
The analysis of complex matrices always poses the ultimate challenge to the analytical chemistry community with regards to targeted and untargeted analyses. The major reason being sample preparation and separation strategies always seek to guarantee “cleaner extracts” that provide enough analyte enrichment while ensuring negligible instrument contamination and matrix effects. In the process, to date, sample preparation approaches for the analysis of complex matrices are characterized by multiple and tedious steps that most often require larger solvent volumes, with low throughput.
For nearly two decades, targeted analysis of contaminants in food commodities has been mostly carried out by the QuEChERS (quick, easy, cheap, effective, rugged, and safe) method, which upon its introduction revolutionized the field of food analysis with a simplified sample preparation approach compared to conventional methods. The popularity of this technique and the copious applications developed in many analytical laboratories around the world led to its implementation as a standard method (European Standard Method EN 15662.2008 and the AOAC 2007.01) and its use by various regulatory agencies (United States Department of Agriculture [USDA], US Food and Drug Administration [FDA], European Food Safety Authority [EFSA]) (1).
Another sample preparation technique was developed in the early 1990s, solid-phase microextraction (SPME) (2), and it emerged for the analysis of contaminants in food. However, at the time, its application was confined to headspace approaches (HS) because of the scarcity of robust extraction phase coatings for complex food matrices. HS-SPME provided optimized and fully quantitative methods for multiresidue analysis of various food matrices, which involved greener and faster protocols with minimized use of organic solvents. In addition, the SPME devices were reusable for multiple sampling cycles, thus lowering the ecological impact of the analytical protocols.
The main limitation of these HS-SPME approaches, however, was the limited vapor pressure of most of the targeted analytes (pesticides, in particular), which affects the limits of quantitation (LOQ) achievable because of low partition of targeted analytes into the sample HS. In light of this limitation, the need for a matrix-compatible, robust SPME extraction phase became indispensable for any further extension of the technique to direct analysis of complex matrices.
The first report of a robust and reliable coating for direct-immersion (DI) SPME in food samples was released in 2012 (3). The new SPME coating consisted of a modification of an already commercially available extraction phase (polydimethylsiloxane [PDMS]-divinylbenzene [DVB]) over-coated with a smooth, thin layer of PDMS that prevented the attachment of matrix constituents that were responsible for the deterioration of the classical SPME coatings and high background in the obtained chromatograms. Subsequently, several methods were developed that demonstrated not only the robustness of the new SPME device toward direct exposure to untreated food samples, but also its superior performance compared to that of the QuEChERS method.
In particular, different reports (4,5) indicate that, in comparison studies with QuEChERS, the DI-SPME methods developed with the new matrix-compatible coating provided the following benefits:
- Simplified analytical throughput (Figure 1) with ease of automation of the technique.
- Comparable or improved LOQ and accuracy values for the targeted analytes.
- Introduction of “cleaner” extracts of targeted analytes into the analytical system, resulting in less populated chromatograms.
Moreover, a quick and effective pre- and post-desorption cleaning protocol further enhanced the coating lifetime. It is important to mention that the parameters associated with cleaning steps should be optimized according to the type and matrix composition for the most effective results (6).
Among the advantages of matrix-compatible SPME coatings, the minimization of instrument contamination, matrix effects, and chromatographic interferences is very important to guarantee unbiased results and high method throughput. This characteristic of the coating is especially useful for the direct coupling of the technique to mass spectrometry (MS), since interferences related to the sample matrix are significantly minimized (7). In fact, the use of matrix-compatible coatings on SPME devices with alternative geometries--for example, SPME transmission mode (SPME-TM)-enabled the rapid screening and quantitation of pesticides in various food matrices at low parts-per-billion levels by direct analysis in real time (DART) ionization coupled to benchtop and portable instrumentation (8,9).
Regarding untargeted screening and metabolomics-targeted analysis, matrix-compatible coatings offer the unique benefit of enabling the extraction of a very broad range of chemical features because of the direct exposure in the targeted matrix (compared to classical HS-SPME). The ability of the technique to provide a comprehensive snapshot of the chemical composition of certain biosystems, in addition to its miniaturized and portable geometry, makes it amenable to in vivo and on-site sampling (10,11).
Considering the numerous benefits related to the use of this new device within the “SPME tool box,” rapid growth in the number of applications and methods developed can be envisioned in the future. We hope those developments will lead to the consequent implementation of the technique for standard methods by regulatory agencies, following the same path as the QuEChERS method.
Recently, research focused on the achievement of a matrix-compatible and antifouling coating for SPME has been very active. Besides PDMS-based matrix compatible coatings, which have been commercially available since 2016, other materials (for example, polyacrylonitrile [12] and amorphous fluoroplastics [13]) have been successively tested and proven to be compatible to biofluids and environmental matrices. Future challenges associated with the use of these types of matrix-compatible coatings will involve the direct analysis of oils and dry matrices for determination of multiclass contaminants.
References
- M.Á. González-Curbelo, B. Socas-Rodríguez, A.V. Herrera-Herrera, J. González-Sálamo, J. Hernández-Borges, and M.Á. Rodríguez-Delgado, TrAC Trends Anal. Chem. 71, 169–185 (2015).
- C.L. Arthur and J. Pawliszyn, Anal. Chem.62(19), 2145–2148 (1990).
- É.A. Souza Silva, Anal. Chem. 84(16), 6933–6938 (2012).
- É.A.S. Silva, V. Lopez-Avila, and J. Pawliszyn, J. Chromatogr. A 1313, 139–146 (2013).
- K.K. Stenerson, T. Young, R. Shirey, Y. Chen, and L.M. Sidisky, LCGC North Am.34(7), 500–509 (2016).
- S. De Grazia, E. Gionfriddo, and J. Pawliszyn, Talanta167, 754–760 (2017).
- H. Piri-Moghadam, F. Ahmadi, G.A. Gómez-Ríos, E. Boyacı, N. Reyes-Garcés, A. Aghakhani, B. Bojko, and J. Pawliszyn, Angew. Chem. Int. Ed. Engl.55(26), 7510–4, doi: 10.1002/anie.201601476 (2016).
- G.A. Gomez-Rios, T. Vasiljevic, E. Gionfriddo, M. Yu, and J. Pawliszyn, Analyst, in press (2017).
- G.A. Gomez-Rios, E. Gionfriddo, J. Poole, and J. Pawliszyn, Anal. Chem., in press (2017).
- S. Risticevic, E.A. Souza-Silva, J.R. Deell, J. Cochran, and J. Pawliszyn, Anal. Chem. 88, 1266–1274 (2016).
- F.C. Fontanive, É.A. Souza-Silva, E. Caramao, C.A. Zini, J. Pawliszyn, L.M. Sidisky, M.D. Buchanan, and D. Vitkuske, Reporter, Appl. Newsl.34.1, 3–7 (2016).
- M.L. Musteata, F.M. Musteata, and J. Pawliszyn, Anal. Chem. 79(18), 6903–6911 (2007).
- E. Gionfriddo, E. Boyaci, and J. Pawliszyn, Anal. Chem.89(7), 4046–4054 (2017).
Janusz Pawliszyn and Emanuela Gionfriddo are with the Department of Chemistry at the University of Waterloo in Waterloo, Ontario, Canada.
Profiling DNA and RNA Modifications Using Advanced LC–MS/MS Technologies
Hailin Wang and Weiyi Lai
The analysis of DNA and RNA modifications is at the cutting edge of epigenetics-orientated biological sciences, and intensive interest is also emerging in the fields of environmental toxicology and health, pharmaceutics, and medicines. DNA 5-methylcytosine (5mC) is one well-known epigenetic modification that does not change the genetic coding information, but may regulate gene expression (1). Recently, it was found that 5mC can be oxidized as catalyzed by ten-eleven translocation protein family dioxygenases to form 5-hydroxymethylcytosine, which can be iteratively oxidized to form 5-formylcytosine and 5-carboxycytosine. These new modifications may be pertinent with active and passive DNA demethylation. Moreover, they may also play critical roles in mammalian cells by themselves. Several groups have also shown a new potential epigenetic mark, DNA N6-methyladenine modification, in high eukaryotes (2−4). Currently, 36 chemical modifications have been found in DNA (DNAmod database, last updated on August 28, 2016), and more than 120 modifications were found in RNA. Interestingly, the RNA modifications are also involved in many important biological processes; for example, N6-methyladenosine (m6A) in mRNA is involved in RNA stability, translation, splicing, transport and localization (5), and m5C in mRNA promotes mRNA export (6). Furthermore, modified nucleosides, as metabolites of DNA and RNA, are potential cancer biomarkers (7).
To understand the abundance, distribution, and functions of the diverse modifications of DNA and RNA, a number of methods have been developed, including bisulfite sequencing, antibody-based enrichment coupled next-generation sequencing, and liquid chromatography−mass spectrometry (LC−MS) (8). Among the known methods, ultrahigh-pressure liquid chromatography−tandem mass spectrometry (UHPLC−MS/MS) is generally one of the most popular methods for the identification and quantitation of DNA and RNA modifications at a global level. In this method, DNA and RNA are subjected to enzymatic digestion into normal and modified mononucleosides, and these mononucleosides are then separated by UHPLC followed by online-coupled MS/MS detection (9,10). Because of the highly efficient separation provided by UHPLC and structure-based MS quantification, UHPLC−MS/MS provides specific and sensitive detection of diverse modifications of DNA and RNA. It is also considered a “golden” method for accurate identification and quantification of diverse DNA and RNA modifications. To date, the development and applications of ultrasensitive and high-throughput UHPLC−MS/MS methods are of great interest to meet the requirement of the study of epigenetics. We summarize current concerns and future perspectives below.
Stationary Phases and Two-Dimensional Separations
Several types of stationary phases have been used to separate nucleosides. Reversed-phase high performance liquid chromatography (HPLC) is popularly used, but many polar nucleosides display poor retention on reversed-phase columns. Ion-pair reversed-phase HPLC is the technique of choice. Although this technique can improve the separation of polar nucleosides, most ion-pair reagents are not volatile and thus are incompatible to the online MS/MS detection. An alternative choice is hydrophilic-interaction chromatography (HILIC). In practice, irreversible adsorption of the polar nucleosides on the HILIC stationary phase was observed in our lab.
Some of the more than 150 (deoxy)nucleoside modifications are difficult to resolve because of the similarity of their structure and polarity. For example, 5mC and N4-methylcytosine (4mC), share the same ion pair for MS/MS quantitative analysis, but their retention on reversed-phase columns are similar. Two-dimensional (2D) chromatography is a promising separation technology for future profiling of these diverse (deoxy)nucleoside modifications.
Rapid and High-Throughput Analysis
We expected more than 10,000 samples per year in our lab. To deal with the large number of samples, we need make the analysis time as short as possible, while minimizing the matrix effects. Rapid and high-throughput UHPLC-MS/MS methods are highly desirable. In these methods, a stable isotope-labeled internal standard should be used to correct the impact of matrix effects.
Ultrasensitive MS/MS Detection
Some mononucleosides are hard to be ionized during electrospray ionization (ESI) and display poor MS/MS detection signal. We showed that ammonium bicarbonate can improve protonation of some nucleosides, and suppress the formation of MS signal-deteriorating metal complexes at the same time (11,12). Yuan and colleagues (13) showed a chemical derivatization of nucleosides for enhancing MS detection. The further improvement of MS detection is of great interest because it can significantly reduce the number of cells and DNA and RNA mass required for single-run analysis.
Online Digestion of DNA and RNA
In general, the digestion of DNA and RNA requires more than 2 h, making it tedious. In this process, some types of modified nucleosides are not stable, such as N6-hydroxymethyl adenine (hm6A) and N6-formyladenine (f6A), the intermediate products of m6A demethylation, with a half-life about 3 h in aqueous solution under physiological relevant conditions (14). If we want to analyze these nucleosides, we need to shorten both the sample preparation and analysis times. Our group constructed a three-enzyme cascade capillary monolithic bioreactor with deoxyribonuclease I, snake venom phosphodiesterase, and alkaline phosphatase on it, which can digest DNA into mono nucleosides when DNA samples flow through it (15). In future research, we will try to couple this capillary bioreactor with MS.
Conclusion
In summary, advanced UHPLC-MS/MS stimulates rapid developments on epigenetic research. On the other hand, the research in the field of epigenetics is also promoting the fast progress of UHPLC−MS/MS technologies to improve sensitivity, hyphenation with online digestion, and high-throughput analysis in the near future.
References
- E. Li and Y. Zhang, Cold Spring Harbor Perspect. Biol. 6(5), a019133 (2014).
- G. Zhang, H. Huang, D. Liu, Y. Cheng, X. Liu, W. Zhang, R. Yin, D. Zhang, P. Zhang, J. Liu, C. Li, B. Liu, Y. Luo, Y. Zhu, N. Zhang, S. He, C. He, H. Wang, and D. Chen, Cell 161(4), 893−906 (2015).
- E. L. Greer, M. A. Blanco, L. Gu, E. Sendinc, J. Liu, D. Aristizábal-Corrales, C. Hsu, L. Aravind, C. He, and Y. Shi, Cell 161(4), 868−878 (2015).
- Y. Fu, G. Luo, K. Chen, X. Deng, M. Yu, D. Han, Z. Hao, J. Liu, X. Lu, L.C. Doré, X. Weng, Q. Ji, L. Mets, and C. He, Cell 161(4), 879−892 (2015).
- B. S. Zhao and C. He, Genome Biol.16(1), 43 (2015).
- X. Yang, Y. Yang, B. Sun, Y. Chen, J. Xu, W. Lai, A. Li, X. Wang, D.P. Bhattarai, W. Xiao, H. Sun, Q. Zhu, H. Ma, S. Adhikari, M. Sun, Y. Hao, B. Zhang, C. Huang, N. Huang, G. Jiang, Y. Zhao, H. Wang, Y. Sun, and Y. Yang, Cell Res.27(5), 606−625 (2017).
- W. Struck, D. Siluk, A. Yumba-Mpanga, M. Markuszewski, R. Kaliszan, and M.J. Markuszewski, J. Chromatogr. A1283, 122−131 (2013).
- M. Helm and Y. Motorin, Nat. Rev. Genet.18(5), 275−291 (2017).
- R. Yin, S. Mao, B. Zhao, Z. Chong, Y. Yang, C. Zhao, D. Zhang, H. Huang, J. Gao, Z. Li, Y. Jiao, C. Li, S. Liu, D. Wu, W. Gu, Y. Yang, G. Xu, and H. Wang, J. Am. Chem. Soc. 135(28), 10396−10403 (2013).
- D. Su, C.T.Y. Chan, C. Gu, K.S. Lim, Y.H. Chionh, M.E. McBee, B.S. Russell, I.R. Babu, T.J. Begley, and P.C. Dedon, Nat. Protoc.9(4), 828−841 (2014).
- R. Yin, S. Liu, C. Zhao, M. Lu, M. Tang, and H. Wang, Anal. Chem. 85(6), 3190−3197 (2013).
- R. Yin, J. Mo, M. Lu, and H. Wang, Anal. Chem. 87(3), 1846−1852 (2015).
- Y. Tang, S. Zheng, C. Qi, Y. Feng, and B. Yuan, Anal. Chem. 87(6), 3445−3452 (2015).
- Y. Fu, G. Jia, X. Pang, R.N. Wang, X. Wang, C.J. Li, S. Smemo, Q. Dai, K.A. Bailey, M.A. Nobrega, K. Han, Q. Cui, and C. He, Nat. Commun.4, 1978 (2013).
- J. Yin, T. Xu, N. Zhang, and H. Wang, Anal. Chem.88(15), 7730−7737 (2016).
Hailin Wang and Weiyi Lai are with the State Key Laboratory of Environmental Chemistry and Ecotoxicology in the Research Center for Eco-Environmental Sciences at the Chinese Academy of
Sciences in Beijing, China.
Measuring More from Less: The Evolution of Hyphenated and Combined Measurements
Jonathan Sweedler
One long-term goal of measurement science is to obtain greater chemical information from smaller samples in a faster, more robust manner. However, while the demands on analytical methods intensify, many of our measurement approaches have reached their practical limits of performance. Over the past few decades, one successful solution has been to link a number of individual techniques to measure the same sample, often achieving the goal of pooling the merits of each. Perhaps no other area has reaped the rewards of combined measurements as much as the separation sciences have.
Obviously, instrumental hyphenation is not new: It is appropriate to contemplate Tomas Hirschfeld’s thoughts, published almost 40 years ago in a special issue devoted to the topic of “hy-phen-ated methods” (1), wherein he stated: GC−MS, LC−MS, GC−IR, LC−IR, TLC−IR. . . . As the rising tide of alphabet soup threatens to drown us, it seems appropriate to look at the common denominator behind all of these new techniques, and those we have not heard from. The hyphen which is the single common constituent of all these acronyms is also the symbol of their common principle.
Hirschfeld anticipated that characterizing more-complex samples would require more-complex instrumental combinations, better separations, and smaller samples-certainly accurate predictions. Accordingly, the first stage of many hyphenated instrument platforms is a separation. The combination of liquid chromatography (LC) with chemical characterization approaches, including mass spectrometry (MS) and nuclear magnetic resonance (NMR) spectroscopy, are now commonplace, as are combining separations and mass spectrometry with themselves multiple times (for example, multidimensional separations and multiple-stage mass spectrometry [MSn]).
A key objective of a hyphenated approach is to obtain a more complete chemical characterization of a sample. Often, spatial or temporal information is also needed, but is usually not acquired with a separation. It is partly to address this deficiency that combinations of hyphenated measurements on the same samples are increasingly being reported. An overarching goal is to increase the information content from the sample along new dimensions.
So, what hyphenated combinations are appearing? Among many possible directions, an important area of focus is advancing the ability to probe large numbers of individual cells for their activity and chemistry (2,3). Although gas chromatography (GC)−MS and two-dimensional (2D) electrophoresis characterizations of individual neurons were reported in the 1970s (4,5), recent approaches such as capillary electrophoresis (CE)−MS now allow greater proteome and metabolome coverage from selected individual cells (6,7), while direct matrix-assisted laser desorption−ionization (MALDI)−MS provides less comprehensive chemical information but from thousands of cells (8,9). Can such disparate measurement approaches be combined? Because a MALDI−MS measurement leaves a significant amount of sample behind, we recently demonstrated high-throughput single-cell MALDI profiling with the ability to perform CE−MS on selected cells (10). This workflow, illustrated in Figure 1, can be used to obtain MALDI−MS and CE−MS information from the same cells (Figure 2). The ability to perform detailed chemical assays on selected locations of a tissue after MALDI-MS highlights the importance of the order of measurement and sample compatibility. As a different example, several groups are combining vibrational spectroscopic imaging with MS imaging (11,12); these combinations are effective because at least one of the measurements leaves the sample behind for the next measurement.
What does the future hold for these measurement combinations? As long as several of the measurements are mostly nondestructive, they can be used sequentially on the same sample. A potential, intriguing application I expect to see in the future--combining electrochemical imaging to monitor cellular release, followed by MS imaging and discrete chemical measurements via LC−MS or CE−MS-should provide a time, space, and chemical map from a living neuronal network.
The trend toward combining higher information content measurements will certainly continue. Regardless of the specific combinations used, separations hyphenated to MS will play prominent roles because of their ability to provide unmatched chemical information from complex samples. Expected advances in the coming decade will allow us to probe a living assembly of cells with the trio of chemical-spatial-temporal resolution as never before possible.
References
- T. Hirschfeld, Anal. Chem.52, 297A (1980).
- The National Institutes of Health Common Fund program on Single Cell Analysis.
https://commonfund.nih.gov/singlecell/ .
- The 2016 NSF sponsored workshop “Measuring the Brain: From the Synapse to Thought.”
http://tinyurl.com/yag2935z .
- R. Ruchel, J. Chromatogr.132, 451−468 (1977).
- T.M. Liffe, D.J. McAdoo, C.B. Beyer, and B. Haber, J. Neurochem.28, 1037−1042 (1977).
- R.M. Onjiko, S.A. Moody, and P. Nemes, Proc. Natl. Acad. Sci. U.S.A. 112, 6545−6550 (2015).
- J.T. Aerts, K.R. Louis, S.R. Crandall, G. Govindaiah, C.L. Cox, and J.V. Sweedler, Anal. Chem. 86, 3203−3208 (2014).
- E.T. Jansson, T.J. Comi, S.S. Rubakhin, and J.V. Sweedler, ACS Chem. Biol. 11, 2588−2595 (2016).
- T.D. Do, T.J. Comi, S.J. Dunham, S.S. Rubakhin, and J.V. Sweedler, Anal. Chem.89, 3078−3086 (2017).
- T.J. Comi, M.A. Makurath, M.C. Philip, S.S. Rubakhin, and J.V. Sweedler, Anal. Chem.89, 7765−7772 (2017).
- T. Bocklitz, K. Bräutigam, A. Urbanek, F. Hoffmann, F. von Eggeling, G. Ernst, M. Schmitt, U. Schubert, O. Guntinas-Lichius, and J. Popp, Anal. Bioanal. Chem. 407, 7865−7783 (2015).
- D.R. Ahlf, R.N. Masyuko, A.B. Hummon, and P.W. Bohn, Analyst139, 4578−4585 (2014).
Jonathan Sweedler is the James R. Eiszner Family Endowed Chair in Chemistry and the director of the School of Chemical Sciences at the University of Illinois at Urbana-Champaign in Urbana, Illinois.
A Glimpse into the Rapidly Evolving and Expanding Field of Separation Science
Jared L. Anderson
The complexity of analytes and their accompanying matrices creates considerable challenges for today’s separation scientists, particularly for the analysis of biological samples. Nevertheless, the field continues to match these challenges with new advancements that I believe will continue to mature over the next decade. The separation and analysis of complex samples should involve a suitable sample preparation method that is capable of eliminating matrix components which are detrimental for downstream chromatographic or electrophoretic separations and mass spectrometry (MS) analysis. It is my observation that the importance of sample preparation is often either overlooked or downplayed with greater attention being focused on the chromatographic separation or MS analysis. Part of the reason for this lack of recognition may be due to the fact that many sample preparation approaches used today are confined to kits that can be readily purchased and used without perhaps a complete understanding by the scientist as to how the approach works.
Looking ahead in the field of separation science, I believe there will continue to be major advancements in automation that will drive the coupling of sample preparation to chromatographic platforms. Automation is particularly important in laboratories that require a reliable and customizable route toward high-throughput analysis. Sample preparation methods that require the separation of analytes from complex components within the matrix will be important in areas ranging from biological to environmental and food analysis. Sample preparation methods suitable for both gas chromatography (GC) and high performance liquid chromatography (HPLC) will continue to be developed, with new and novel platforms becoming popular. The miniaturization of sample preparation techniques using selective sorbents or solvents will ensure high enrichment factors while drastically minimizing costs, particularly in disposal.
I believe that the field is poised to see tremendous advancements in the use of three-dimensional (3D) printing to develop customizable substrates for chromatographic separations. Brett Paull and co-workers at the Australian Centre for Research on Separation Science have recently reported fascinating results where polymer thin layer chromatography platforms were printed and used for the separation of dyes and proteins (1). In yet another report from this year, Gertrud Morlock and co-workers at Justus Liebig University in Germany demonstrated the printing of thin silica gel layers for use in planar chromatography (2). These are among the growing number of reports in which 3D printing has been shown as a viable approach to customize a 3D separation platform but to also do so through the combination of numerous printing materials that are on the market today. Now I fully understand that there may be some skeptics out there that may question the overall scope of platforms and applications that separation scientists could fulfill with 3D printed separation devices. However, did you know that 3D printing is already making its way into the food industry and is expected to revolutionize the way in which food products are prepared and produced in the future? The dropping costs of 3D printing technologies make this area rich for exploration in separation science. I believe that advancements in material science will not only allow us to easily modify the substrate that accommodates the chromatographic bed, but will also enable us to have fine control over the ordering of the 3D printed stationary phase. This will permit separation scientists to produce highly customizable separation media. Although a number of technical challenges including the need for fine resolution of printing and the time required to print at such resolution still remain, 3D printing in separation science is an area that I predict will see tremendous growth over the next decade. These innovations will also transform the field of sample preparation. Just this year, Leandro Hantao and co-workers from several institutions in Brazil reported the production of 3D printed microfluidic systems that incorporated on chip solid-phase extraction for the sample preparation of petroleum before GC separation (3). Imagine being able to quickly 3D print a column, precolumn, or sample preparation cartridge with customized stationary phases and sorbents within your own lab! I look forward to seeing separation scientists, engineers, material scientists, and computer scientists all working together to make these advancements a reality!
References
- N.P. Macdonald, S.A. Currivan, L. Tedone, and B. Paull, Anal. Chem. 89(4), 2457−2463 (2017).
- D. Fichou and G.E. Morlock, Anal. Chem.89(3), 2116−2122 (2017).
- E.M. Kataoka, R.C. Murer, J.M. Santos, R.M. Carvalho, M.N. Eberlin, F. Augusto, R.J. Poppi, A.L. Gobbi, and L.W. Hantao, Anal. Chem.89(6), 3460−3467 (2017).
Jared L. Anderson is a professor of analytical and bioanalytical chemistry with the Department of Chemistry at Iowa State University in Ames, Iowa.
The Future of the Extra Dimension in Liquid Chromatographic Separations
André de Villiers
Exorbitant demands being placed on analytical separations by fields such as proteomics, natural products, and biopharmaceuticals have elicited remarkable performance gains in high performance liquid chromatography (HPLC). However, it is also true that, barring a paradigm shift in column design and instrumentation, one-dimensional (1D) LC ultimately cannot meet the separation requirements imposed by such complex samples. As a consequence of the diminishing returns encountered for high-resolution separations-analysis time increases much more dramatically than the peak capacity does-the practical limit of state-of-the-art 1D-LC separations lies in the region of peak capacities of 1000. Considering that the available peak capacity should significantly exceed the number of sample components to improve the probability of their separation (1), the challenge is clear.
Currently, the most promising means to obtain an order of magnitude increase in performance for liquid-based separations is comprehensive two-dimensional (2D) LC (LC×LC) because of the oft-cited multiplicative increase in peak capacity that is attainable. Indeed, having just returned from the 45th International Symposium on High Performance Liquid Phase Separations and Related Techniques (HPLC 2017) conference in Prague, Czech Republic, it was gratifying to see a noteworthy increase in the number of contributions involving 2D-LC. This increase seemingly indicates that multidimensional (MD) LC has successfully bridged the gap from a primarily research-based technique to one increasingly being applied to solve real-world separation problems in industry. Here, I would like to share some thoughts on the reasons underpinning this evolution, and the potential of future developments in the field that might further increase the performance and application of MDLC.
The two most-used modes of 2D-LC are online comprehensive (LC×LC) and (multiple) heartcutting ([M]HC) 2D-LC. With the availability of robust and reliable instrumentation, MHC is ideally suited for regulated environments and to meet particular separation goals, although the performance gain is not sufficient for untargeted separation of complex samples. In such cases, LC×LC, where the entire sample is subjected to separation in two different columns, is required. Although LC×LC has been around for a long time (2), widespread use of the techniques was hampered by several constraints. Developments that have played a role in overcoming these challenges include important fundamental contributions, improvements in high-speed and high-performance columns (notably ultrahigh-pressure liquid chromatography [UHPLC] and core-shell columns), and instrumentation. More recently, the availability of commercial MDLC instrumentation has arguably had the greatest impact on the growing use of the technique: In contrast to the situation only 5 years ago, where most LC×LC separations were performed using laboratory-built systems, the availability of “off-the-shelf” hardware with dedicated software has made 2D-LC accessible to many more scientists. Indeed, new applications demonstrating the power of LC×LC are being published weekly in the literature, with peak capacities up to a few thousands attained for conventional analysis times.
However, several aspects still have to be addressed before LC×LC will find more widespread use. One of these is method development, which, similar to the performance of the technique, is much more complex than in 1D-LC. Important contributions have been made in terms of kinetic (3) and selectivity (4) optimization, although much further work is required to provide the tools for nonspecialists to overcome the expertise barrier. A second, more fundamental limitation of online LC×LC has to do with the very fast 2D separations required to meet 1D sampling criteria; this speed requirement ultimately restricts the peak capacity attainable in LC×LC. While off-line (and stop-flow) LC×LC provide peak capacities on the order of tens of thousands because of the removal of 2D separation time constraints, this performance also comes at the cost of much longer analysis times. An alternative strategy is to perform LC×LC separations in space (xLC×xLC) as opposed to in time (tLC×tLC). The principal advantage of this approach is that all 2D separations are performed in parallel, which allows better performance than tLC×tLC for the fast separation of complex samples (5). Practically, the benefits of xLC×xLC have yet to be demonstrated, although researchers are actively involved in this area (6).
Despite the contemporary success of tLC×tLC, the performance of the technique remains inadequate for the most complex samples currently encountered in liquid-phase separations: protein and peptide samples, which may contain in excess of 10,000−100,000 molecular species. It is therefore not surprising that researchers are contemplating the use of a third separation dimension.
The potential of comprehensive three-dimensional (3D) LC has long been recognized, and indeed 3D size exclusion chromatography (SEC)×reversed-phase LC×capillary electrophoresis (CE) was already implemented in a landmark paper in 1995 (7), although it is only recently that renewed interest has resulted in active exploration of the further potential of this approach (8−11). Currently, much of this work is based on theoretical considerations on the best way to achieve optimal performance in 3D-LC; practical implementation remains an exceedingly complex task (which emphasizes the achievement of Jorgenson in 1995). There are different ways of achieving this goal by combining spatial and time-based separations. Studies indicate that the performance gains of tLC×tLC×tLC are relatively limited because of the decreasing performance of each dimension due to sampling constraints, as well as significant dilution (9,10). In contrast, xLC×xLC×xLC potentially provides the best performance in terms of peak production rate (peak capacity/total analysis time). However, design and analyte detection represent major challenges in any such potential system. xLC×xLC×xLC is considered a more feasible approach, since compounds may be detected as they are eluted from the third dimension (10,11). While much of the work in comprehensive 3D-LC currently remains theoretical, this approach is essential in pointing the way to practically achieve the exceedingly ambitious goal of attaining peak capacities close to 1 million.
Although not involving chromatographic separation, the role of ion mobility (IM) in combination with MDLC separations is another interesting direction for future research. In IM, gas-phase ions are separated based on their averaged collision cross sections (CCSs) through transfer across a drift tube filled with buffer gas. In addition to the utility of the technique for facilitating compound identification by MS, IM also potentially allows separation of isobaric compounds, and therefore provides a complementary separation mechanism to MS, and indeed to many chromatographic modes. The relevance of the technique to comprehensive MD separations stems from the fact that IM separations are performed in the millisecond timescale, which allows the technique to meet the sampling requirements of LC×LC separations. This, therefore, opens the options for comprehensive 3D-LC×LC×IM separations. There are also significant challenges to overcome here, primarily in terms of data analysis and representation, although recent work on LC+LC×IM confirms the promise of the approach (12).
From the above, very brief, overview, it can be concluded that
- despite astonishing improvement of the performance of 1D HPLC-the magnitude of which is often not sufficiently appreciated by contemporary chromatographers-the current limit remains insufficient for the analysis of the most complex samples of relevance today,
- the additional separation dimension in tLC×tLC (and (M)HC 2D-LC) increasingly provides a feasible means of solving complex separation problems, and
- exciting times lie ahead in the development and implementation of comprehensive 3D-LC.
It is clear that significant challenges remain in the latter fields, but the extraordinary benefits promised by each provide the clear incentive to continue this extremely rewarding journey.
References
- J.M. Davis and J.C. Giddings, Anal. Chem. 55, 418−424 (1983).
- F. Erni and R.W. Frei, J. Chromatogr. 149, 561−569 (1978).
- G. Vivo-Tuyols, S. van der Wal, and P.J. Schoenmakers, Anal. Chem. 82, 8525−8536 (2010).
- B.W.J. Pirok, S. Pous-Torres, C. Ortiz-Bolsico, G. Vivo-Truyols, and P.J. Schoenmakers, J. Chromatogr. A1450, 29−37 (2016).
- D.J.D. Vanhoutte, G. Vivo-Truyols, and P.J. Schoenmakers, J. Chromatogr. A 1253, 39−48 (2012).
- E. Davydova, S. Wouters, S. Deridder, G. Desmet, S. Eeltink, and P.J. Schoenmakers, J. Chromatogr. A 1434, 127−135 (2016).
- A.W. Moore and J.W. Jorgenson, Anal. Chem.67, 3456−3463 (1995).
- P.J. Schoenmakers, G. Vivo-Truyols, and W.M.C. Decrop, J. Chromatogr. A 1120, 282−290 (2002).
- G. Guiochon, N. Marchetti, K. Mriziq, and R.A. Shalliker, J. Chromatogr. A1189, 109−168 (2008).
- E. Davydova, P.J. Schoenmakers, and G. Vivo-Truyols, J. Chromatogr. A 1271, 137−143 (2013).
- B. Wouters, E. Davydova, S. Wouters, G. Vivo-Truyols, and P.J. Schoenmakers, S. Eeltink, Lab. Chip15, 4415−4422 (2015).
- S. Stephan, C. Jakob, J. Hippler, and O.J. Schmitz, Anal. Bioanal. Chem.408, 3751−3759 (2016).
André de Villiers is an associate professor in the Department of Chemistry and Polymer Science at Stellenbosch University in Stellenbosch, South Africa.
Articles in this issue
almost 9 years ago
Another Milestone in the Books for LCGCalmost 9 years ago
Where Separation Science Is Headingalmost 9 years ago
Method Adjustment for Gradient Elutionalmost 9 years ago
UHPLC, Part II: Benefitsalmost 9 years ago
The Secrets of Successful Temperature Programmingalmost 9 years ago
Vol 35 No 8 LCGC North America August 2017 Regular Issue PDFAdvertisement
Related Content
Advertisement


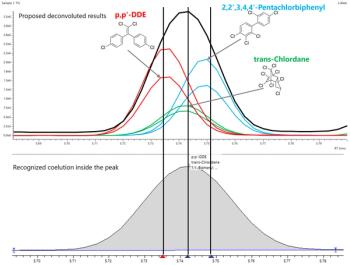

Advertisement
Advertisement
Trending on LCGC International
1
Sample Preparation Strategies for PFAS Analysis
2
GC-MS/MS Links Tooth-Layer Pollutant Traces to Autism Risk
3
The PFAS Analyst’s Wish List
4
AI/ML in Practice: Machine-learning Prediction of Chromatographic Retention Times for Small Molecules in Pharmaceutical Applications
5