Best of the Week: PFAS Detection, LC Troubleshooting, Deep Learning in Proteomics, and More
Published: | Updated:
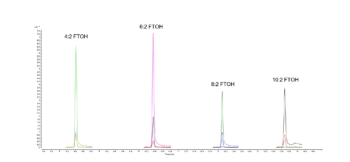
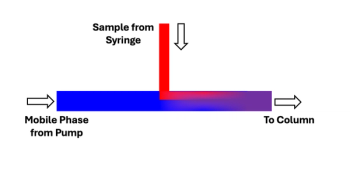
This week's Chromatography Online highlights span LC solvent mismatch solutions, advanced PFAS monitoring by GC–MS and TD–GC–MS, deep learning in DIA proteomics, multidimensional LC–MS for plant extracts, PEG column guidance, and LC–MS/MS and GC–MS applications in consumer product safety and disease research.